回顾Qwen系列
Qwen系列
-
Qwen / Qwen 1.5
-
基础模型:1.8/7/14/72B,后来Qwen 1.5又有0.5/1.8/4/7/14/32/72等。在LLaMA基础上调整,关键策略:
- Embedding and output projection不共享(非tie embedding):之前会直接将二者设成互为转置,Qwen改为二者完全独立,提升表示能力(qwen3改为大的不共享小的共享)
- RoPE,但用FP32(更高精度)存inv_freq(好主意)
- Bias处理:去掉了FFN和layer norms里的bias(提高稳定性、稍微减少参数量,来自PaLM),但在QKV layer(就是)这步加上了bias(来自RoPE)
- Pre-Norm & RMSNorm
- SwiGLU
-
Qwen-Chat:RLHF
-
Qwen-Audio,Code-Qwen,Math-Qwen等
-
Qwen-VL (VLM)
-
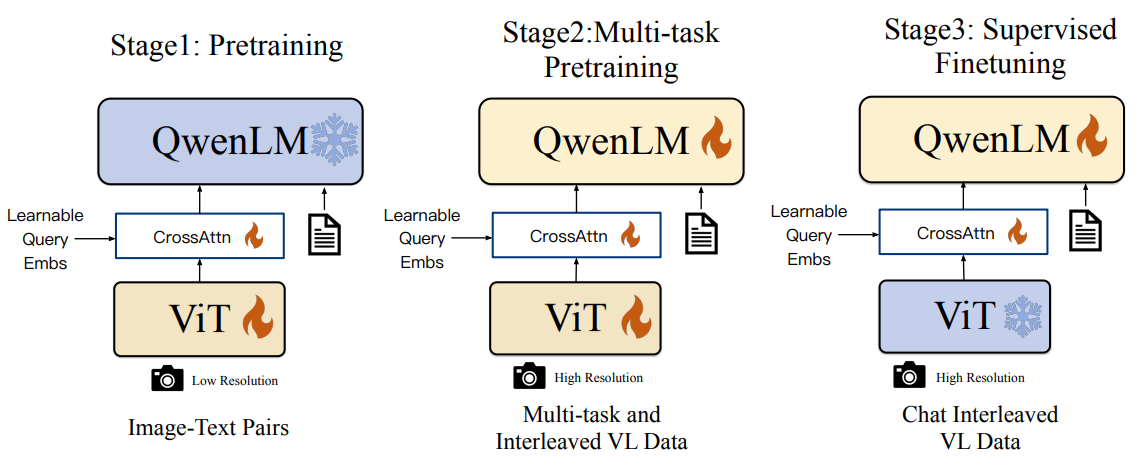
visual encoder:ViT(注:仅1.9B,参数大头还是在LLM上)
-
LLM:pretrained Qwen-7B
-
Position-aware Vision-Language Adapter:其实就是单层cross attention,Q可训练,K就是ViT输出,Adapter即可将视觉特征压缩(其实不止压缩,也有投影或对齐的效果)到固定长度(256),这个结果直接进LLM,(感觉其实基本是简化版Q-Former,当然最后像LLaVA直接进一步简化成MLP了)
-
结构图及训练过程(其实很自然):
- 真正的第一步其实是LLM训练;随后冻结LLM训ViT&Adapter,先利用LLM做初步对齐
- 然后就是正常训练,包含LLM在内的全参数均可训练
- 随后指令微调,由于和视觉无关故冻结ViT
-
Qwen1.5-MOE
- 看起来和普通MoE差不多,就是FFN(FFN参数量一般大于Attention部分)换成MoE
-
-
-
Qwen2
- 基础模型
- GQA,SwiGLU,RoPE,QKV-bias,RMSNorm & pre normalization
- DCA with YARN:见后
- Qwen2-Instruct
- Qwen2-Math
- Qwen2-VL
- Qwen2-Audio
- 基础模型
-
Qwen2.5
- 基础模型
- GQA,SwiGLU,RoPE,QKV-bias,RMSNorm & pre normalization,看起来和qwen2没啥本质区别
- Qwen2.5-Instruct
- Qwen2.5-Math
- Qwen2.5-Coder
- QVQ:Qwen-VL的衍生物,强调多模态推理能力
- QwQ:RL优化推理能力,强调CoT——后面Qwen3就把think和非think整合到一起去了
- Qwen2.5-VL
- Qwen2.5-Omni
- 基础模型
-
Qwen3
-
基础模型:0.6/1.7/4/8/14/32,MoE:30-A3/235-A22(A后面的数就是指单次activate的参数量,单位都是B)
-
GQA,SwiGLU,RoPE,RMSNorm & pre-normalization,去掉QKV bias
-
小参数量模型上用tie embedding(直接把encoder转置当decoder)
-
QK-norm:主要是便于训练
-
数据:多语言、用Qwen2.5-VL从PDF搞额外数据等等
-
训练大致方法
- 通用阶段
- 推理阶段:增加语料库中和推理相关的内容
- 长上下文阶段:最长32K,ABF+YARN+DCA配合使用
- 增大基频
- 把RoPE的基频从10000提升到1000000之类,防止超长序列时相位重叠
- 问题:短距离的分辨力下降(转得很慢),因此要配合其他方法进行处理
- YARN
- PI:在token方向进行缩放,把序列index按比例缩放到特定范围
- NTK:低频不适用PI(避免破坏局部信息),只在高频使用PI(处理长程依赖)(有个阈值来分别低频和高频)
- Attention scaling:和普通的在QK^T下面加的temperature是一个东西
- 以上三种方式直接整合到Positional encoding的计算公式里去,因此不会引入额外开销
- DCA,Dual Chunk Attention
- 长输入分块,每块长度和预训练长度相同
- intra chunk:正常算
- inter chunk:对距离较远的块先压缩(比如K、V直接用块内均值代替),给这个均值代表元分配一个新的基于RoPE且不超出范围的的位置编码(这里有很多细节),最后正常用Q和均值KV算attention即可
- successive chunk(连续块处理):魔改RoPE加一个位置偏移量(这里也有很多细节),然后正常算;如果不连续的话偏移量就会太大导致超出RoPE能处理的范围了(OOD)
- 增大基频
-
-
Qwen3-Embedding
-
Qwen-Image,Qwen-Image-Edit
-
Qwen3-Next
-
Qwen3-Omni
-
Qwen3Guard
-
Qwen3-VL
-
Qwen3-Coder
-
Qwen3-Max
-
Qwen-Long
-
