重点回顾LLaMA系的重要节点,很多trick都是老朋友了
LLaMA1
架构
这里重点分析LLaMA1究竟和最原始的decoder-only架构有哪些区别
-
这里的Pre-和Post-指的是norm是放在MHA以及FFN前面还是后面(当然放后面就得放在add后了),二者主要的区别是post版的不易训练,pre更容易训练(这里有一些数学推导需要注意)。
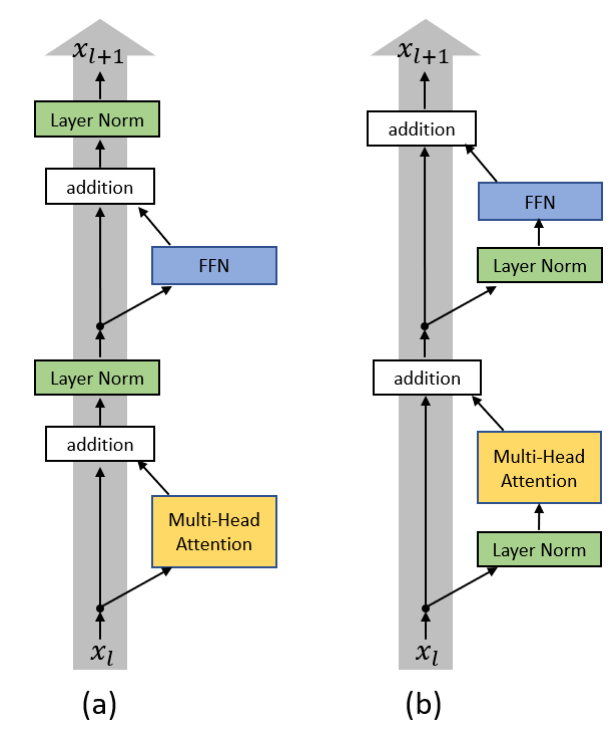
-
另一方面也把layernorm换成了RMSNorm,主要是出于减少计算量的考虑(下面的是可学习参数,通常不会像batchnorm一样加偏置项)

-
SwiGLU
- 传统的ReLU–GPT3 GELU–LLaMA SwiGLU
-
RoPE
数据和训练
- 参考Chinchilla对Scaling law的修正,认为模型大小和数据大小要平衡(同等增加)
- 只使用public data
- 开源,公开训练细节
LLaMA2
大体和InstructGPT相似,主要的差异在LLM结构上,除1代的特征外其它最大的差异是GQA
LLaMA3
除数据量、性能提升外,值得注意的突破有两方面:
- context window:4096(LLaMA2)👉8192(LLaMA3初期)👉128K(LLaMA3后续)
- multi-modal
LLaMA4
-
MOE(稀疏化)
-
Early Fusion的multi-modality
- LLaMA3是在训完纯文本的LLM后,用adapter把vision信息(通过ViT等)finetune进去,具体可以参考LLaVA的玩法
- LLaMA4则是从一开始就把image patch token和text token混合预训练(这部分细节需要考究)
-
window干到10M或1M
-
iRoPE
- 有的层有RoPE,有的层没有(即NoPE),NoPE层有助于学习全局的、上下文无关的信息
- (当然还有其他方面的小调整)
-
attention temperature
- 原理其实和采样温度差不多(采样温度是加在输出部分的softmax里),用来让attn部分的softmax输出更锐利一些,以突出长程context中的重点
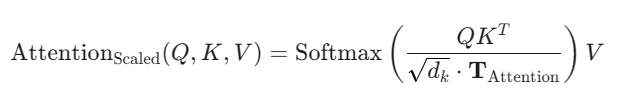
-
-
注:LLaMA4可能大有问题,看看技术得了,之后找qwen的仔细看看