LLM关键的topic/milestone,整理思路。
重新整理LLM关键的topic/milestone
Language Models are Few-Shot Learners (2020)
- GPT-3:175B
- 风格化的结构简图

- ICL,重新定义了ICL语境下的zero-shot/few-shot(这些data (examples)都是在prompt里给的,没有param update)
- 验证scaling law
Training language models to follow instructions with human feedback (2022)
- InstructGPT: make progress on aligning language models by training them to act in accordance with the user’s intention (follow a broad class of written instructions)
- RLHF: reinforcement learning from human feedback
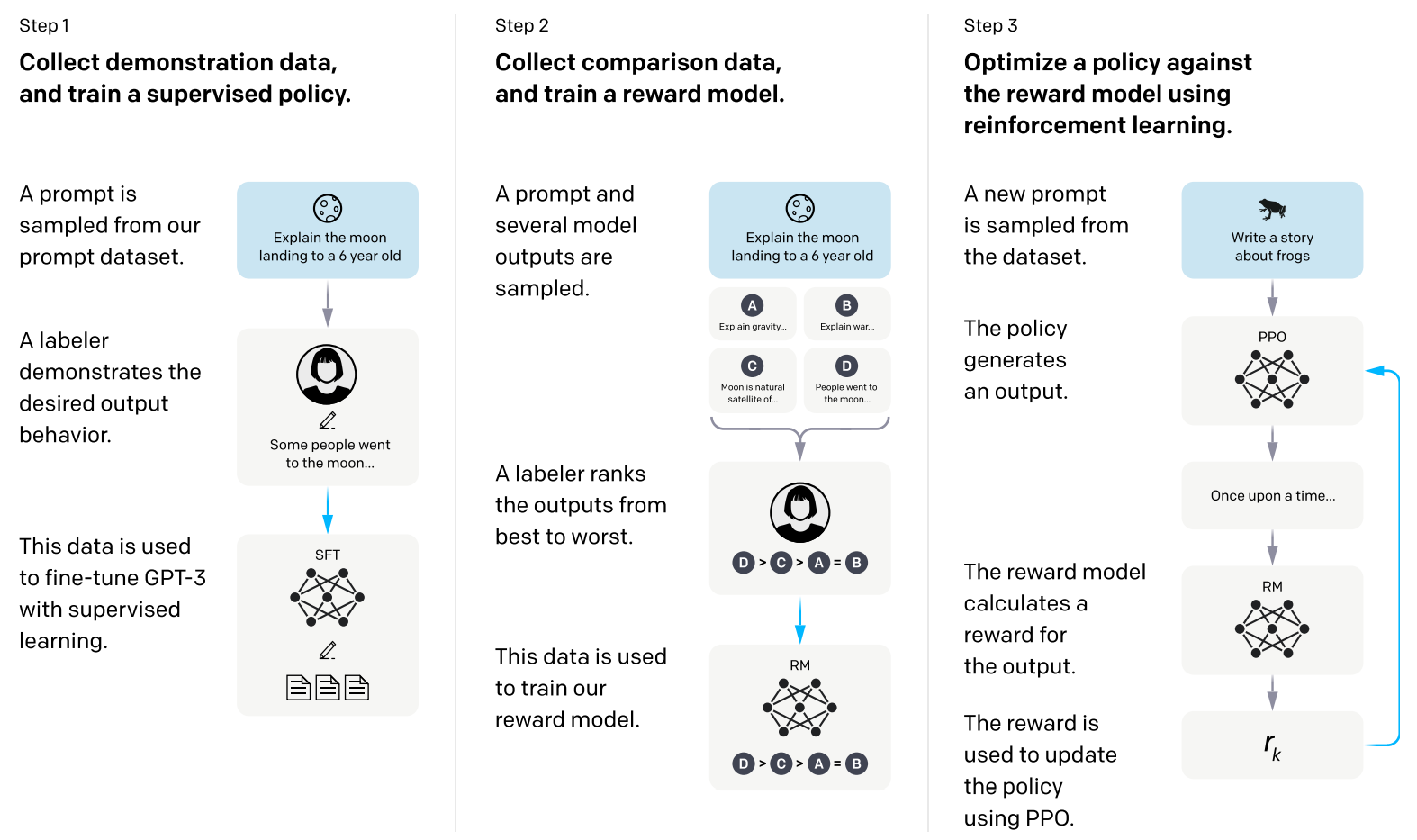
- RLHF其实应该分成两部分
- SFT:在~13k人工指令-回答数据上微调
- 当时用的是全量微调,现在自然可以上LoRA
- 考虑到PPO的收敛稳定性问题,这一步其实对回答进行了较强的约束(给了一个高质量的起点),否则直接RM+PPO搞不好根本训不出来(或者不稳定、效率低下)
- RM + PPO
- RM
- 一个LLM(推荐用6B之类小点的)把输出头改成标量输出
- 标注员给一堆(4~9)SFT后的LLM生成的答案排序,然后这堆答案会生成若干带有人类偏好的答案对,与问题一起塞进RM即可输出标量分数
- 训练RM时极大化分差即可(具体loss形式参见paper),最后加个bias中心化(也是为RL考虑)
- PPO
- 首先明确:被训练的还是LLM的参数(当然这里也可以变成LoRA),文中给的objective其实相当于PPO的reward,后面怎么GAE-clipping纯粹是PPO的事,并不在那个objective公式的范围内
- 为什么不能只用SFT?
- SFT用crossentropy更倾向于逐token与训练数据逼近,从宏观来看类似于逼近训练数据的平均行为,但平均行为不一定是最优的(e.g.符合人类偏好的回答很可能是以整句整句为单位分立的,把一堆好回答embedding完进行平均得到的回答未必是好回答)
- VQVAE,VQGAN道理类似
- SFT对数据质量要求较高,RL这部分排序速度快,对标注员要求也低一些
- SFT用crossentropy更倾向于逐token与训练数据逼近,从宏观来看类似于逼近训练数据的平均行为,但平均行为不一定是最优的(e.g.符合人类偏好的回答很可能是以整句整句为单位分立的,把一堆好回答embedding完进行平均得到的回答未必是好回答)
- RM
- SFT:在~13k人工指令-回答数据上微调
- 进一步讨论
- RM-Free Methods,DPO(闭式loss,直接把RL部分去掉变成监督学习)等
- Automated Feedback,即不要人工标注,RLVR(可量化的reward,案例如GRPO,在RL部分使用新的优势估计GRAE)等
- ……