简要介绍rotary positional encoding (RoPE)的原理,主要参考RoFormer
经典的(用sinusoidal的)positional encoding直接把positional encoding向量加到输入x上,然后再分别乘各自权重变成qkv。这是一种绝对位置编码,后来也有人将其魔改为相对位置编码(即qk点积的值只和相对距离有关(即paper中的m-n))。
但RoPE直接从“相对位置”这条约束出发,构造了一个只与相对距离有关的变换方式
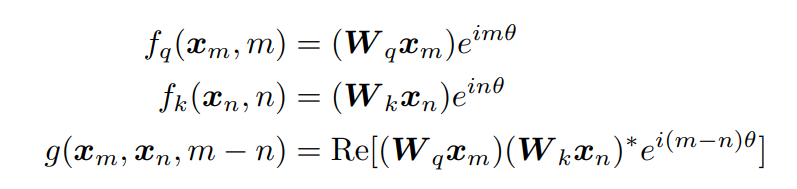
当然这个地方的推导只针对都是2d向量(“二元”的普通复数)的情形,对于高维输入直接两两分组,分别使用旋转矩阵即可,因此完整矩阵形式中的R就是一个分块对角矩阵。如果高维输入是奇数,可以直接抛弃某一维(指这一维只乘1,相当于旋转0度)
关于为什么theta会定为下面的形式
,其中i是embedding方向的index,d是embedding的维度,注意这个公式中不包含序列(token)维度的任何信息,这个式子其实是Sinusoidal位置编码就在用了,RoPE只是借过来继续用
-
编入序列(token)方向信息的方式是给这个角度乘n(n代表序列中的位置)
-
也就是说在embedding方向,index小一些的维度转得快,index大的维度转得慢
-
关于长程衰减性:长程衰减指的就是在token方向上离得越远(即下图中的越大),内积结果就更有可能偏小。下图中的m和n都是token方向的index(其实直观感觉不一定非要像苏这样推,但暂时没想到更合适的方法)

-
为什么可以直接规定index小的维度就是转得快,大的维度转的慢?为什么把转速绑定到特定的embedding方向的维度上是可行的,不会导致特定维度只能提取出与相应转速适配的信息而丢失其他的信息么?(注:面试题)
- 注意:RoPE是在QK proj之后的(参考下图),proj过程中不同embedding维度方向的信息就已经相互接触过了,训练时会自适应地调整的,因此无需担心这个问题
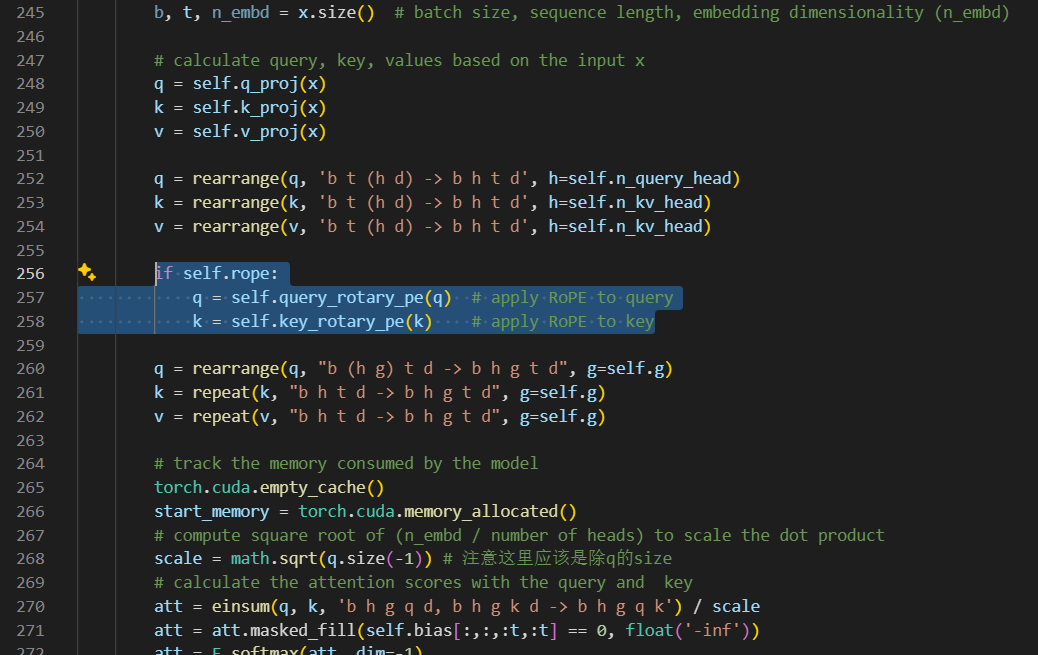
需要注意的细节:
- 经典的positional encoding是加在输入x上的,而RoPE是乘在qkv上而非输入x上的
- 不同2d子空间对应的转角是完全可以不同的,这个值可以自行选取,所以原作者直接借用了sinusoidal的方式。原则上当然也可以训练得到,但以sinusoidal形式定初值后训练中变化不大,因此就直接定为固定值了。
- 分块对角矩阵太稀疏,实际实现时一定要优化成点积和的形式
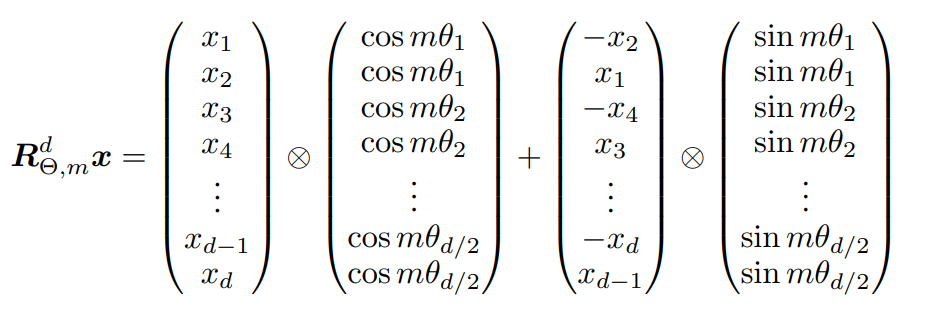
RoPE更详细的介绍可以直接参考原作者的blog。RoFormer文章前半段和blog的内容基本上是一样的。