介绍一个简单但实用的性能上限估计模型roofline,它可以帮助我们估计给定程序优化的极限。
计算模型
假定我们的运算过程是这样的:
- 从DRAM中取出大小为 GB的浮点数据,通过带宽为 GB/s的信道传入CPU中
- CPU以 GFLOP/s的速度进行计算。该任务总共需要吉次浮点运算
于是总用时为 (单位:s)
定义计算密度(arithmetic intensity)为,则AI表示均摊到单位数据上所需要进行的计算次数,通常和算法本身联系较强。若AI较大则称为计算密集型程序,否则称为访存密集型程序。
据此有:实际的计算速度为 (单位:GFLOP/s)。这里忽略了大量额外所需的时间,因此这个计算速度是程序性能经过优化的上限(roofline)。如果程序性能已经非常接近这个值,则可能表示继续优化的空间不太大了。
以AI为自变量作出实际运算速度的变化曲线,即得(紫色空心线):
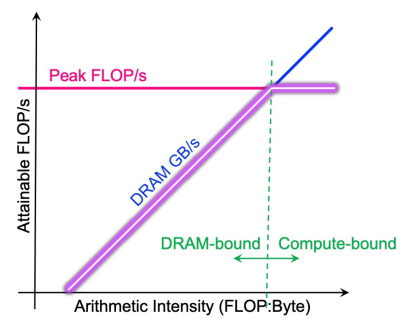
据此可形象地得出:
- 计算密集型程序主要受CPU计算速度的限制,访存密集型程序主要受访存带宽的限制
- 程序是计算密集还是访存密集可以通过其AI、CPU计算速度、带宽三个量进行估计
Reference
[1] Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009), 65–76. https://doi.org/10.1145/1498765.1498785