介绍关于Cuda程序优化的知识。
CPU执行模型
-
硬件组织层次:GPU——SM——warp——core
-
软件概念层次:Grid——线程块——线程束——线程
- GPU = SMs + global memory + constant memory + L2 cache
- SM = warps + (shared memory + L1 cache)
- 有的GPU可以控制shared memory和L1 cache的比例,但总容量是固定的。
- warp = cores + registers
-
CUDA程序 = Host程序 + Device程序 (通过函数修饰符区分)。考虑函数嵌套(父子)和运行位置的组合一共有三种组合:
__global__:被CPU上运行的函数调用,在GPU执行的函数。- 即通常说的内核函数(kernel)。
- 只能修饰
void类型的函数。 - 调用时使用最特殊的
<<< >>>标志。
__device__:被GPU上运行的函数调用,在GPU执行的函数。__host__:被CPU上运行的函数调用,在CPU执行的函数。不加修饰符默认为__host__类型
此外,也可以使用
__host__ __device__表示同时生成两个版本的代码。但二者均不能和__device__混用。注意不能由GPU调度CPU做某事,故为3种而非4种组合。
有时CUDA编译器会对
__device__作自动内联。可以通过__noinline__或__forceinline__手动指定是否内联。 -
注意:若硬件资源够,则一个SM可以同时执行多个线程块
warp
- SM上调度的最小单元。一个warp包括32个线程。
- SIMD(32个线程必然是相同指令)
- SM上有warp scheduler(硬件单元)
- 当一个进程束的下一条指令操作数就序时即有被调度执行之资格,因此线程束执行顺序是不可预期的
- 当出现内存等待(如cache miss)时,对应进程束被换出
- 线程块的维度只是逻辑概念,实际调度时就是拉直后32个一组调入warp
- 示例:
dim3 blockSize (40,2);,则实际的warp分配情况如下图: 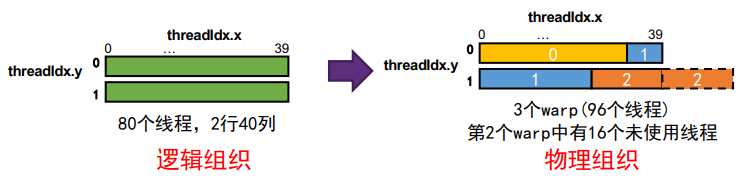
- 示例:
warp发散(warp divergence)
- 同一个warp内不同线程执行不同分支就是线程发散,该warp必须执行多次(每次解决一个分支,其余线程废弃),效率严重下降
- 不同warp之间的分支没影响
- 但**是否在同一个warp中需要根据拉直后32个一组的方式判断!**不能看线程块维度(因为这只是逻辑概念,例如前面的例子中,按照
threadIdx.y的值分支还是会触发warp发散!) - 解决:以warp size作为分支粒度(可使用宏
warp_size等)
GPU存储层次
以下列出的只是容量的典型值,不同GPU有一定差异。
-
寄存器——线程,256KB/SM,平均每线程在KB级左右,且寄存器个数也有上限(如255个)
-
共享内存——线程块,共享内存和L1 cache一共128KB/SM
-
不能跨SM(线程块)复用数据
-
定义方式:使用
__shared__变量修饰符-
静态定义:显式指定空间大小(普通变量、定长数组等),如:
__shared__ float smem[32]; -
动态定义:调用kernel的
<<< >>>中指定大小,如:extern __shared__ float smem[]; -
注意动态定义给的地址是相同的,因此如果想定义多个内存共享空间时可以手动偏移:
extern __shared__ float* smem;float* smem1 = smem;float* smem2 = smem + shared_size_of_smem1;
-
-
-
全局内存——核心,16~32GB等(就是平时说的显存)
- 有L2 cache,为6MB
- 在host端通过
cudaMalloccudaMemcpycudaFree之类控制。
-
本地内存——分配到线程,但位置在全局内存,性能差
- 仅当编译阶段发现寄存器容量不够时(“寄存器溢出”),才不得不把多的数据搬到本地内存。
- 尽可能控制每个线程的空间使用量,不要被迫使用本地内存。
-
常量内存——核心,仅可读,位置同全局内存
Sector
- 在全局内存(DRAM)、L2 cache、L1 cache之间传输数据的最小单元
- 通常是32Bytes(和架构相关)
- 访问一次sector称为一个transaction,transaction个数直接决定访存性能
- 1个cache line则是4个sector
常见优化
- 通信次数与通信量、缓存与数据重用、预取以重叠计算访存
- GPU占用率 = SM运行线程数 / SM最大支持线程数
- 有nvprof之类工具查看
- 矛盾:线程数
- 太少:占用率低,硬件利用率小,……
- 太多:寄存器、共享内存等资源有限,不希望溢出到本地内存。
- 其他:
- 循环展开:减少分支。可以
#pragma unroll 4之类自动展开 - 原子操作:GPU有预定义的原子操作,性能比普通操作有下降
- 循环展开:减少分支。可以
数据传输
- 重点优化Host和Device之间的数据传输
- 传输数据量尽可能小
- 多次小传输合并成单次大传输
- 异步,计算通信时间重叠
- page-lock等
- 固定内存
- 把主存一个页面直接映射到GPU,系统会自动cudaMemcpy,用的时候如同在使用主存。性能有所下降,但有时会比手动copy快(有的CPU架构会对此做特殊优化)
- 接口:
cudaHostAlloccudaHostGetDevicePointer等 - 但数据可重用时海慧寺尽可能用全局内存/共享内存
- 异步
cudaMemcpy等是同步的,传输完才能返回- 有专门的async版本函数。此函数在host端是异步的,即不待传输完毕就返回。(但device端应该还是需要等待传输完成的)
- kernel函数则本来就是异步的,CPU端在GPU启动运行后,不等GPU端执行完毕就返回了
- Stream
- 对应kernel调用
<<< >>>的Sid参数 - 相当于并行执行不同的kernel函数,执行顺序不固定。
- 可以配合
cudaMemcpyAsync之类使用。
- 对应kernel调用
全局内存
-
合并访存
-
如:硬件会自动判断一个warp的load指令的目标地址是否连续,若是则自动合并。故尽可能让数据满足这一要求。
-
AoS,SoA:互为转置
- array of structure(AoS)
- structure of array(SoA),通常这种更优(例如我们都想访问structure中的第一个位置,则SoA才是连续地址,可以合并访存)
-
手动合并访存:直接先存在共享内存中(共享内存没有连续问题),攒满了再统一放到GPU去
-
-
访存对齐:最小访问粒度为sector(32bytes),因此要对齐32bytes的格位(不然就可能会多访问一个sector)
-
示例:矩阵乘
- 注意CGMA指标(计算访存比compute to global memory access),要把CGMA提高到计算和访存性能差异的倍数上才能充分发挥性能
- 由于shared memory不够大,则用分块算法
- CGMA也未必越大越好
共享内存
- 需要用户手动管理,变量标识符
__shared__ - 组织形式:bank,一个bank为32bit(4Byte),每隔128Byte为bank共用(电路层面决定)的周期
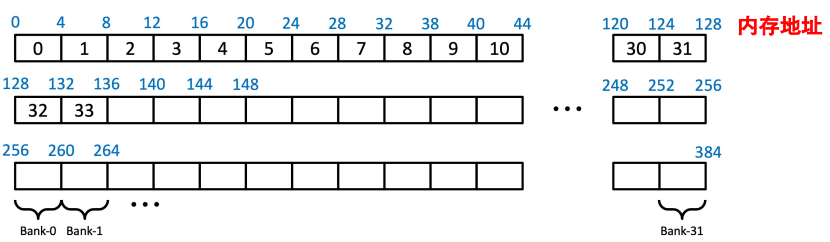
- bank conflict
- 同一访存周期内,每个bank只能服务1个请求。故同一个warp内访问处于同一bank对应的地址时,则访问请求会自动变为串行的,性能大大降低,这就是bank conflict
- 注意:不同warp的访存是独立调度的,因此不会出现bank conflict
- 可以使用profile等工具检查
- 解决:共享内存扩充,如下两图对比:
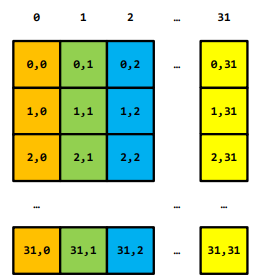
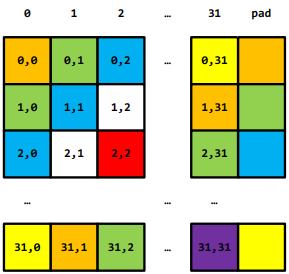
- 同一访存周期内,每个bank只能服务1个请求。故同一个warp内访问处于同一bank对应的地址时,则访问请求会自动变为串行的,性能大大降低,这就是bank conflict