从原理角度介绍MPI。
点对点通信
缓冲区
- 非阻塞通信:用户buffer可能会在发信彻底完成前被修改,因此需要系统控制的Local buffer(或称System buffer)作为中介。
- user data – local buffer – network – local buffer – user data
- 当user data被拷贝进local buffer后,非阻塞通信函数即可返回
- 不用等待通信,但更耗费空间
- 可以使用
MPI_Test,MPI_Wait等判定通信状况。在通信结束前访问接收缓冲区是未定义行为。 - 在通信中可以进行计算。即计算通信重叠
- 阻塞通信:用户buffer直接进入网络。因此在通信结束前必须等待。
- user data – network – user data
- 减少空间使用,但需要等待。
- 注意拷贝耗时远比通信耗时低,因此时间层面上没有什么优势
协议
- Eager协议
- 不管对方有没有开始recv,发送方都直接强行把数据通过网络传进接收方的buffer
- 延迟低,但接收进程必须时刻要有充分大的buffer
- 多在进程数少时传小消息
- Rendezvous:类似握手协议
- 先通信(发个信封,包含大小等信息),对方的recv返回ack才开始发送数据
- 延迟高,不需要额外的空间,则多用于传大消息
- 可以不需要local buffer,减少一次潜在拷贝
- 注意:Eager和Rendezvous与是否阻塞无关
- MPI会根据数据大小、进程数等因素自动选择两个协议之一。选择标准和具体实现相关。这可能会对是否发生死锁有影响。
死锁
以下代码可能产生死锁:
1 | MPI_Status st; |
注意:特定情况下是否发生死锁和MPI的具体实现、数据大小等因素可能有关系。例如以上代码在数据量小时,MPI可能会选择Eager协议,于是发送方不用等待接收方的回应即可把数据全部硬灌进网络中,因此可能不死锁。在数据量大时,MPI选择Rendezvous于是自然会死锁。
解决方法:
- 调整合适的通信顺序
MPI_Sendrecv:通常的实现是MPI_Isend + MPI_Irecv + a pair of MPI_WaitMPI_Bsend:返回表示user buffer中的内容已经被完全拷入local buffer,因此此时user send buffer已经可以被任意修改访问了,也可以选择直接释放掉user send buffer。由于无论选择哪个协议,返回时都不需要接收方的消息,因此可以避免死锁。(参考:https://stackoverflow.com/questions/42606441/mpi-bsend-usage)MPI_Isend:返回表示MPI将在未来适当时刻进行发信。此时修改user send buffer是危险的(这些操作应该在MPI_Wait后才能进行)。
在很多情况下,同步都是没有必要的(阻塞通信隐含了一次同步),多余的同步可能浪费带宽。
进程映射
- 进程间通信需求不同,不同进程之间的通信速度也不一样
- 进程究竟放在哪台机器:进程映射——图映射问题(NP-Complete)
- Block
- Cyclic
进程绑定
- 希望把进程绑定在某个cpu的核上,以节省切换开销、减少cache miss等,提升性能
集合通信
图源:https://wgropp.cs.illinois.edu/courses/cs598-s15/lectures/lecture29.pdf
Bcast(broadcast)

实现:
- 扁平树:root进程依次向其他进程发信,简单但浪费带宽
- 二项树:适合短消息
- Van de Geijn(Scatter + Allgather):通信少,适合多进程长消息
- Ring
Gather、Scatter
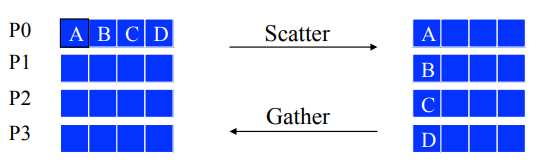
- Scatter可以仿照Bcast用二项树算法解决
Allgather

实现:
- Ring:长消息
- Bruck:短消息
- Recursive Doubling:中等长度消息
Alltoall

实现:
- Bruck:短消息
- Recursive Doubling:短消息
- Irecv-Isend:直接大量发送收取,中等长度消息
- Pairwise Exchange:长消息
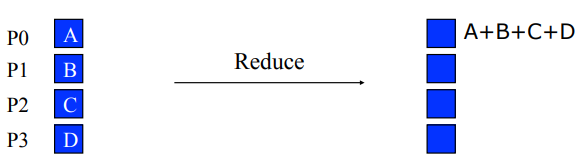
Reduce
Allreduce
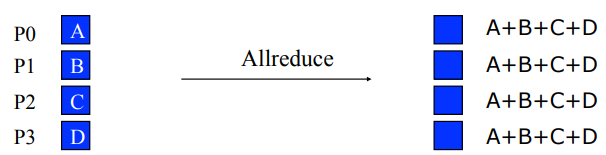
- 等价于Reduce + Bcast
- ML传递梯度最经典的方案
实现:
- Ring:reduce-scatter + allgather
性能模型
- :把大量小消息合成一个大消息能节省时间
- 更精细:LogP模型
性能分析
- PMPI_接口:真正的MPI函数核心功能,可以被MPI_函数包装,可以自行定制计时功能
- mpiP:PMPI实现,链接库
MPI_Wtime等也可- 基准测试程序:OSU,测试运行环境的情况