简要介绍正则表达式。
正则语言(Regular language)、正则表达式(Regular expression)
定义
- 正则表达式的递归式定义
-
最简单的正则表达式(递归基)
- 空集,对应的正则语言就是空集
- 空串,对应的正则语言就是
- 任意单字符,对应的正则语言是
-
进一步定义其他正则表达式(表示正则表达式对应的正则语言)
-
或:
-
连接:
-
(克林)闭包:
-
- 能用正则表达式表示的语言就是正则语言()
示例
- 例:由构成的四位数的正则表达式:
- 例::
- 表示若干个(0个~任意个)1
- 于是对应的正则表达式可以写成
- 即把符合条件的串剪成两个0两个0的段,当然要小心没有0的串!
- 例:,对应的正则表达式
- 例::
- 首先00和11这两种正则表达式可以随便放,即
- 总长必然是偶数,因此可以两位两位地看
- 显然01,10这两种子串出现的总次数也是偶数;11、00这两种子串则可任意多
- 于是把00+11当成1,10+01当成0,即转化为上面已解决的问题
- 即
- 当然,正则表达式未必唯一
- 正则表达式和NFA类似,没法在多项式时间内最小化。但DFA的最小化是可以在多项式时间内完成的(这部分内容见后)。
等价性
定理 DFA、NFA和正则表达式能表达的语言都一样(即都能且只能表达正则语言)。
-
证明:DFA和NFA的等价性已证。则以DFA为例,
-
首先考虑为某个DFA找出对应的的正则表达式
-
例:
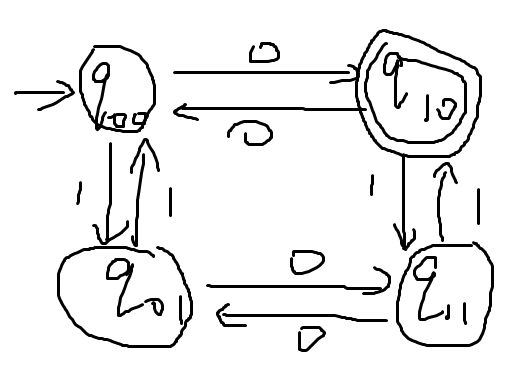
-
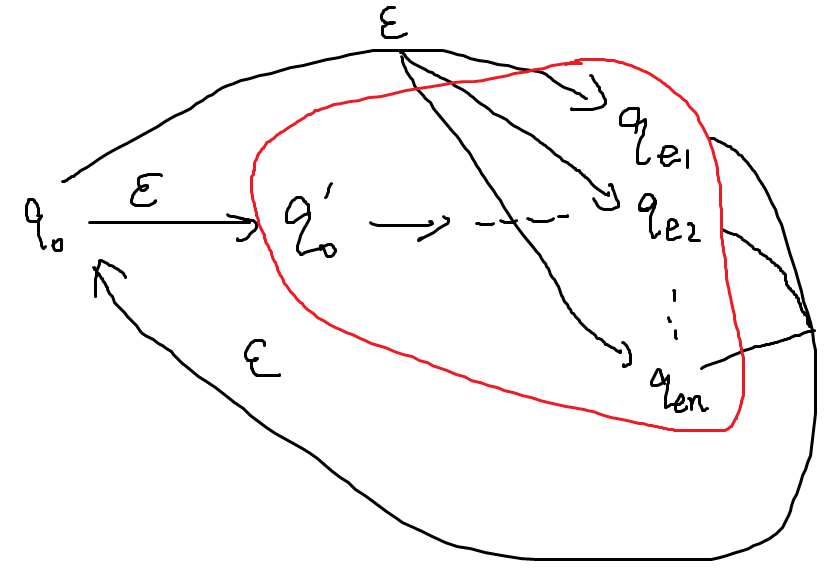
然后添加带正则表达式的边逐步替代普通的边,需要逐个状态地消去,例如下图中就需要添加带正则表达式的边以取代q01状态的功能
-
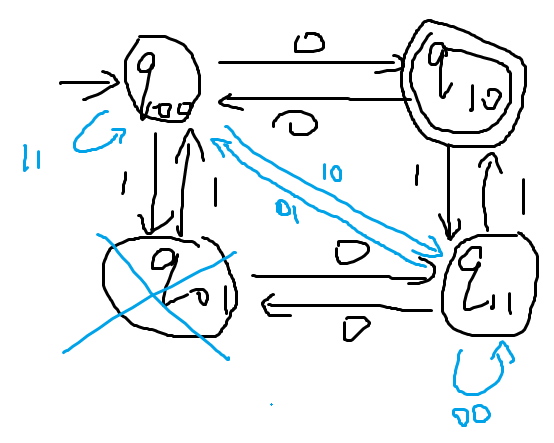
-
在添加四条带正则表达式的边后,q01这个状态所有输入输出都表达过了,所以可以消去了
-
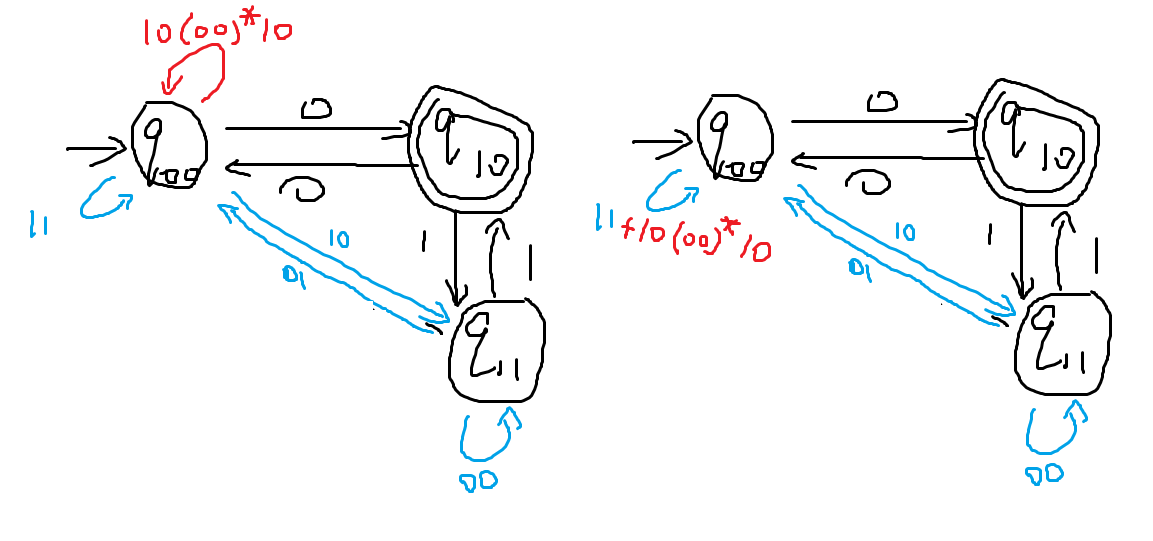
-
同理,接下来需要添加边来取代q11的功能(即只看经过q11的路径),这里需要注意自环要使用*运算,且同始同终的边的正则表达式可以+或起来变成一条边(上图没有完全化简完,仅作示意)
-
最后通常会变成这样一个形式
-
于是可以写成
这部分的严格构造方式:
设DFA 有n个状态,记为所有能从状态到状态,且中途不会经过编号大于的状态的串(或是允许的)所对应的正则表达式。随后动态规划填表即可。
递归式为
注:这个方法显然是多项式复杂度。
-
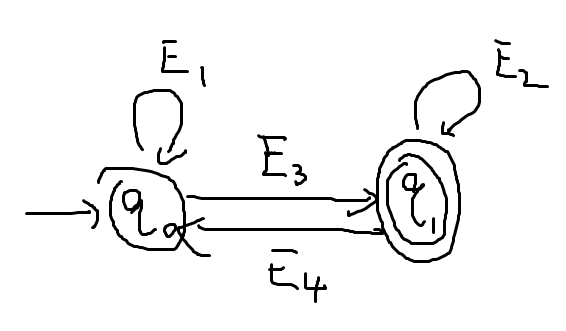
其次考虑为某个正则表达式构造对应的NFA
- 正则表达式本身是递归构造。为递归基构建NFA很容易。
- 然后关注递归规则,当、两个正则表达式都有对应的NFA时:
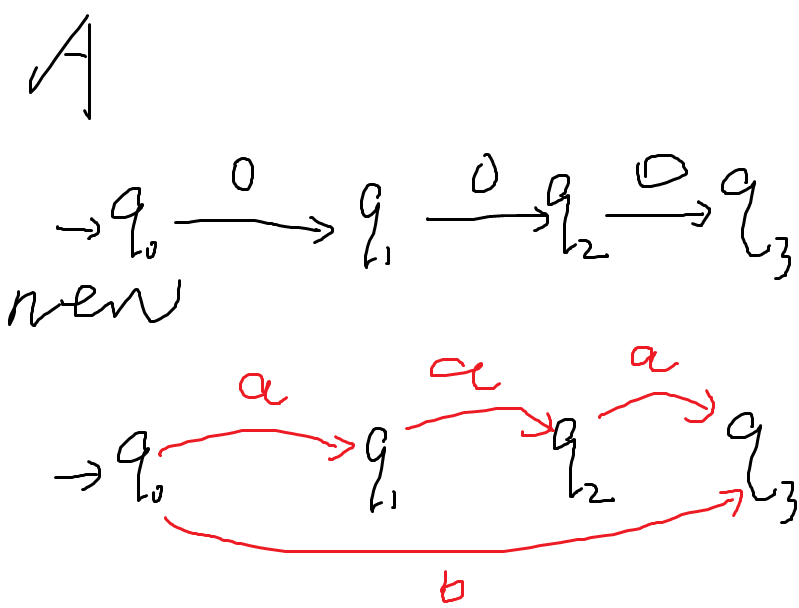
- :注意不能简单地像下图一样并起来
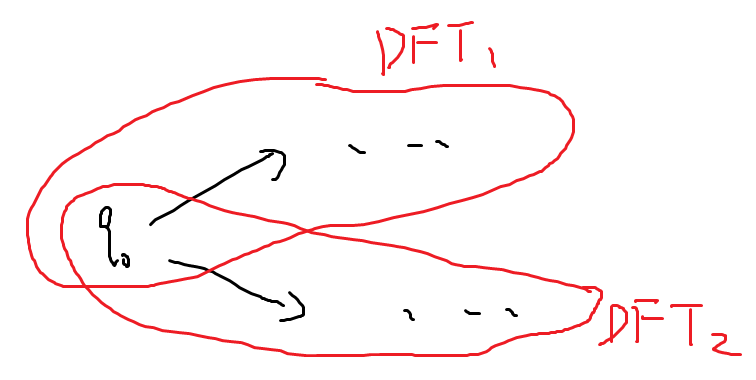
- 例如接受偶数个0和接受3的倍数个0的正则语言是
- 则下图NFA可能接受“00000”,不满足原意
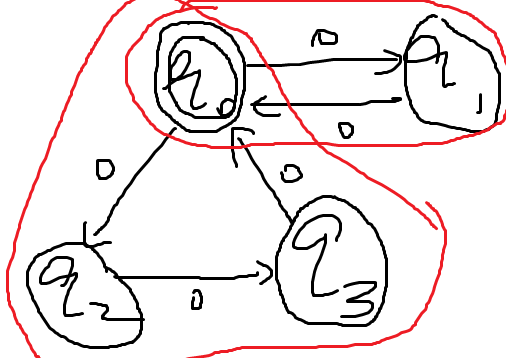
- 于是需要ε-NFA:允许箭头上出现ε,即不读任何东西也能转移,这样就不会退回来导致上面的问题了
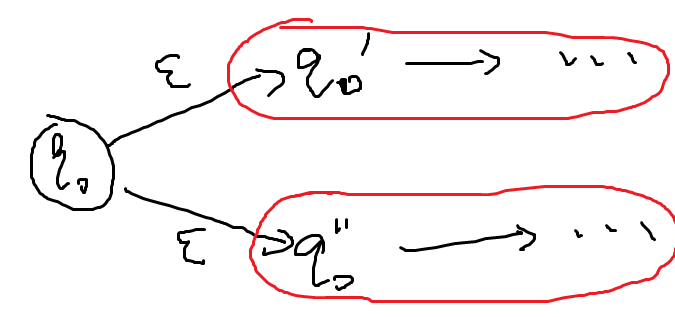
- 现在需要证明ε-NFA和DFA等价,这只需要用和上次课相同的子集构造法即可证明
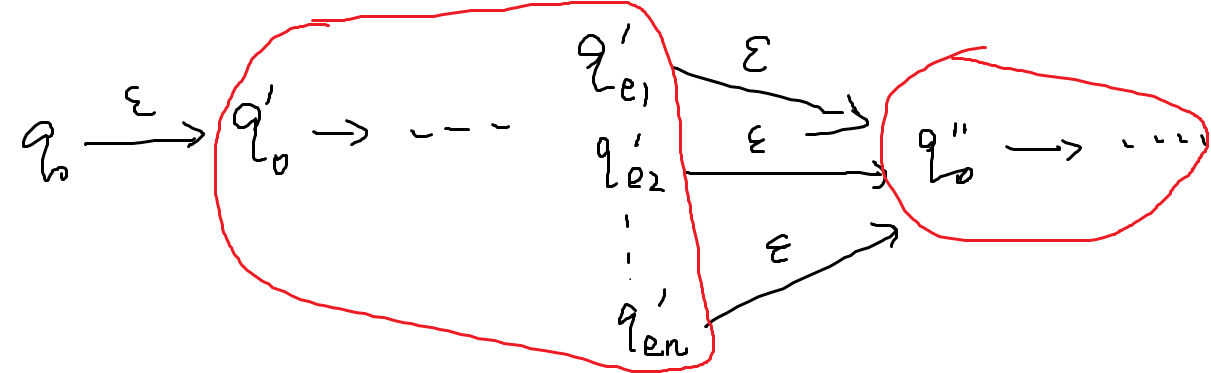
- 用ε-NFA还可以证明和也可以构造对应的ε-NFA,如下所示:
不能计算的东西
定理 存在DFA不能计算的语言
- 注意DFA实际上没有记忆,或者说由于状态有限,因此塞进去太多东西会导致状态重复出错。寻找不可计算的语言就需要由此作为突破口。
- 性质:正则语言的Pumping Lemma
- 设是正则语言,则必然存在一个和有关的自然数,使得中任意的若满足,则一定可以分解成的形式,且
- ,如
- 证明:正则,则存在DFA 使得
- 这个DFA只有有限个状态,则取(取得比大就行,是状态集)
- 当时,设,则都在中,由抽屉原理可知其中必然有重复的状态,这个多次出现的重复状态必然代表了一个有向回路,则将这个回路取作,此前为,此后为即可。
- 利用Pumpling lemma即可提出反例:不是正则表达式
- 反证,假设是正则表达式,则存在M,考虑,则,则和都是一段0,而y可以任意复制增减,于是矛盾。
- 后面有的计算模型可以计算这个语言。
- 考虑把上面的语言取个“反”,即0和1的数量不一样多(注意不是关于取了补集,因为可以有1开头的串!),则这个语言也不是正则的!
- 反证:考虑,则还是分割成,、都是0组成的串,且的长度不会超过,于是的长度就是一个整数,则的前半段多出了个0,于是插在原本的个0中就有了个0,和1的数量相同,导出矛盾
- 其他不能计算的语言:,,
- 第二个例子的证明:正则则存在M,任取素数p>M(隐含地使用结论:素数有无穷多个),则,,取,则长度为合数,故矛盾
- 第三个证明:可以直接用补集转换为对第二个例子的讨论。
- 直接证明则假设正则,则,然后考虑如何取k使得长度变成素数。
- 迪利克雷定理:任意等差数列,只要首项和公差互质,则该数列中有无穷个素数(不互质则显然该数列中没有素数)(该定理的证明需要解析数论)。
- 特例:首项和公差取为1,则可以证明素数有无穷多个;首项取成1,再把公差去成2,3,……则可知有无穷多个素数除2或3或……余1。(不过这个结论和本题无关)
- 于是由于不超过,则取,则本身是合数,且必然和互素,用迪利克雷定理即知随着增加会有无穷多个素数出现,矛盾。
- 其实也有办法可以绕过迪利克雷定理(待补充……
更多性质
- 正则,则也正则(证明和之前DFA一样。注意NFA的此项性质不能直接用补集法证明,需要子集展开后再补集才行)
- 除补集操作外,并交对正则也是封闭的(证明的时候只用把并证明即可)
- 若想直接证明交,则考虑令,……
- 连接、*操作也是封闭的
- 设字母表,存在,设第一个字符表上存在正则语言,则也是正则的。
- 设字母表,存在,设第一个字符表上存在正则语言,则还是正则的。原理:正则语言有一个正则表达式,把正则表达式的符号换成对应的串即可得到的正则表达式。既然有正则表达式那这个语言显然就是正则的。
- 设字母表,存在,设第二个字符表上存在正则语言,定义逆映射,则还是正则的
- 例:,则
- 证明:借助DFA,针对有一个DFA(记为)
- 然后新自动机的构造方法就是针对的每个状态,把和的像输入,看输出能跑到哪里,则新自动机的转移终点就到对应的中的状态,如此逐步地把对应的DFA构建出来
- 例:
- 正则性还可以在许多种变换后得到保持
最小化问题
-
最小NFA和最短正则都是NP-hard
-
但DFA有最小化的高效(多项式时间)算法
-
思想:我们需要合并一些“等价”状态
-
第一步:连通性检查,即不可达状态可以直接去掉。然后才是下面的算法
-
两个状态等价,是指从一个状态读入后被接收等价于从另一个状态读入后被接受
-
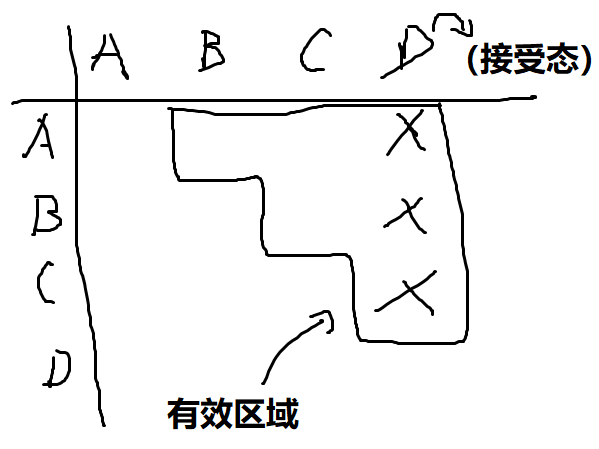
但等价不好检查,我们考虑检查不等价的情况——接受态和非接收态必不等价(注意要考虑到空串!)
-
考虑列表,横纵轴都是各个状态。然后把接受态和非接收态必不等价用上去作为初始条件(如下,ABCD是状态。假设D是接收态,则D和其他状态都不等价,因此有一排叉)
-
然后一对一对地检查,若暂时无法确定是否不等价就跳过,否则就打叉表示不等价
-
检查方法:取某字符同时输入待区分的两个状态,若转移后的两个状态不等价,则这两个状态也不等价。(只要有一个字符导致下一跳不等价就能导出不等价)
-
然后一趟一趟地扫描整张表,若可以确定不等价就打叉,反复多趟直到表在两次扫描后不发生变化,即没打叉的格就是等价的!
-
然后把等价的状态合到同一个状态里,画边即可(只要指向被合状态中的一个即可加边,根据等价性定义知这样总是可以加边)
-
显然,复杂度至多
-
最小性证明,假设这样得到的不是最小的(状态不是最小的),于是考虑设置一组串,这些串在原先简化的自动机中会到达,而更小的自动机中必然会有两个串会到达同一个状态。而这两个串对应的原先简化自动机中的状态是不等价的,于是存在一个串续在这两个串后一个接收一个不接收,但更小的自动机中经过续的必然到达同一状态,产生矛盾。
-
还可以得到判断语言是否等价:把两个DFA一起同时最小化(得到一张大表),结果一样就是两个语言一样。
-
正则表达式也可以转成DFA来化简
-