简介近期若干种基于单帧RGBD输入在Category-level进行位姿估计的方法。(论文链接与引用说明略)
Category Level Object Pose Estimation via Neural Analysis-by-Synthesis
- analysis-by-synthesis
- 不需要具体模型
- RGB/RGBD
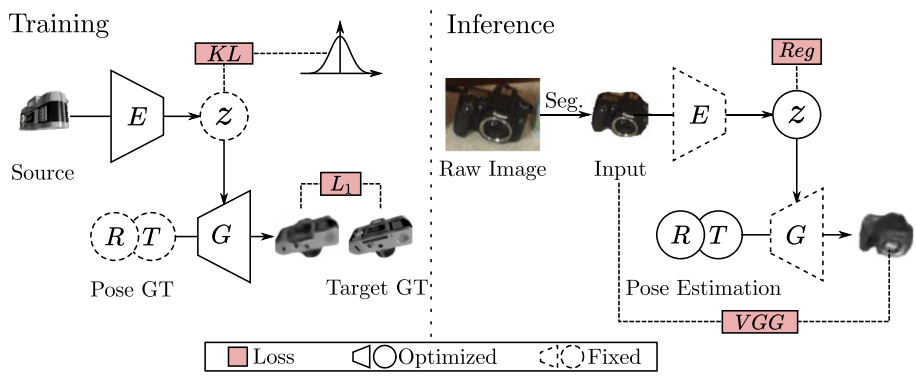
-
Training:就是VAE
-
Inference:迭代式优化初始的z值(由Encoder给出)和初始的R、T位姿值(Encoder、Generator冻结)。损失为:
第一项是原图和生成图各自用预训练的VGG网络提取的特征之差的范数,第二项就是对code的约束。
- 非凸,因此通过不同方式选择多种初值,输出最好的结果。
-
Encoder:就是普通CNN
-
Generator:结构如下
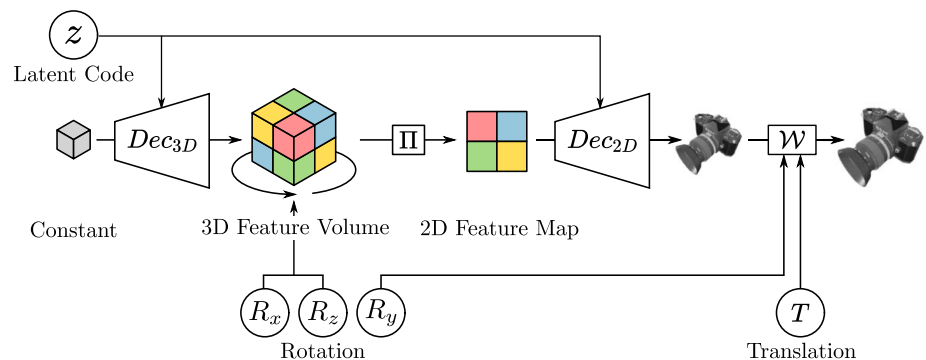
(图上的可能反了),这里的x,y轴是在成像平面的两个轴,z轴是和成像平面正交的轴,z轴的旋转就在成像平面内。
SPD
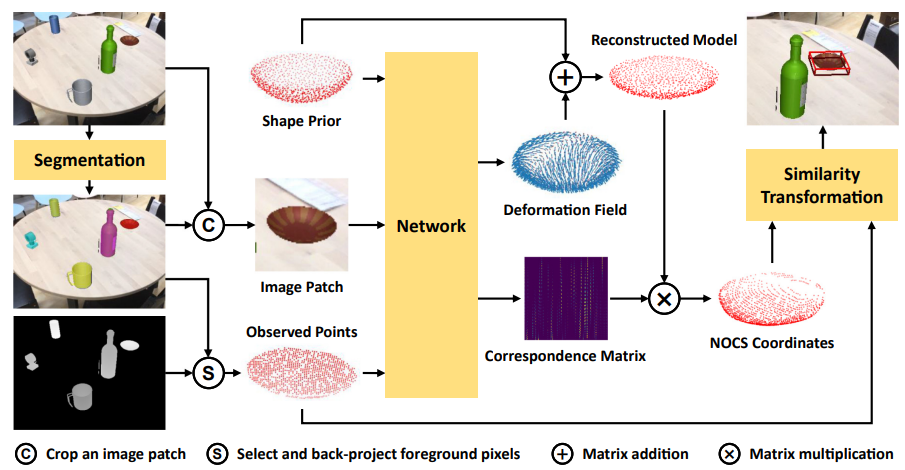
过程非常明了,看图说话。
橙色的Network结构如下:
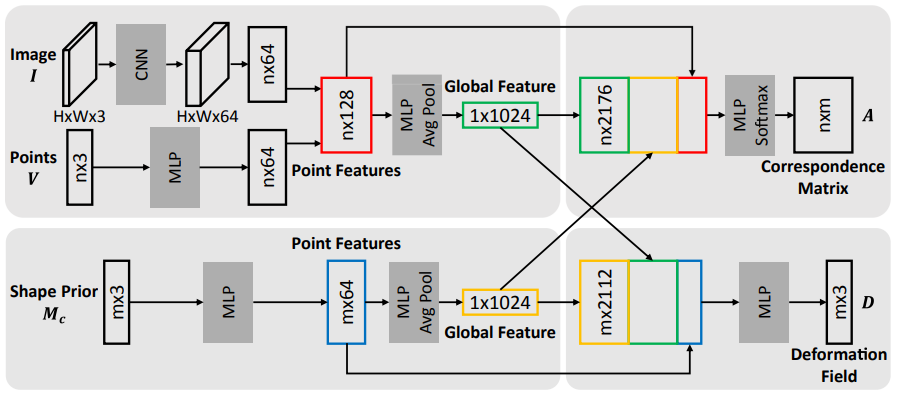
最后一步用梅山算法+RANSAC得出结果。
不过Shape Prior的产生需要说明:通过普通的Encoder-Decoder获取某一类各个实例的code(选用Chamfer distance为损失),最后Shape Prior为这些code的平均值经过Decoder的结果,见下图(按:左下角为code的TSNE可视化结果):
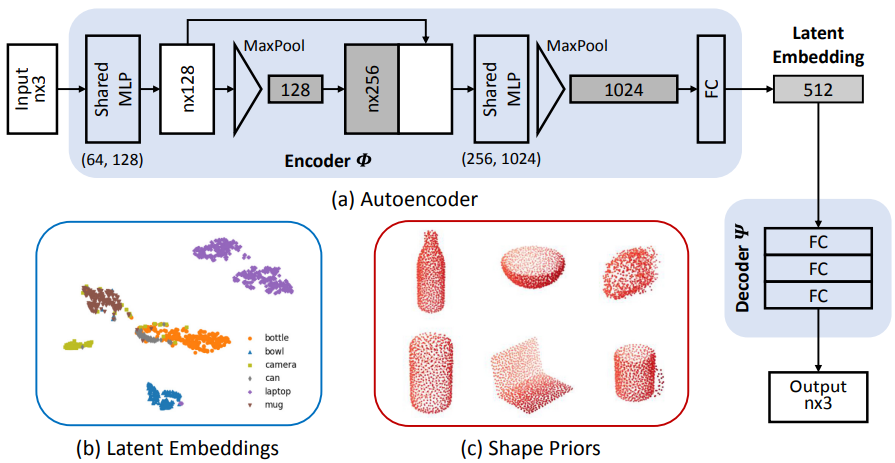
FS-Net
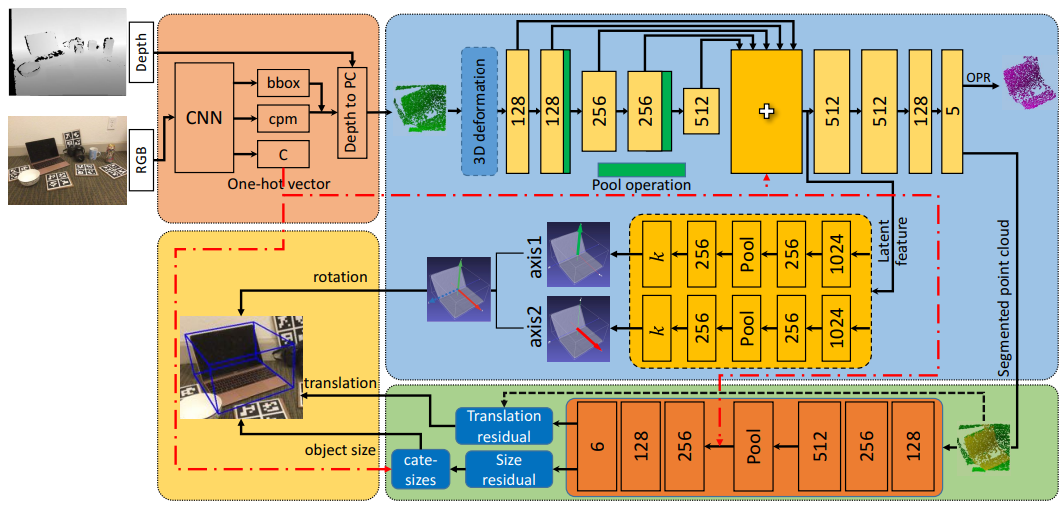
左上角:RGB用yolov3确定bounding box和类别标签(C),切出对应部分的点云(目标物体+少量背景)。
右上蓝色部分:Shape-based Network。
- 首先使用3D deformation用于训练时数据增强
- 随后是autoencoder-decoder段,encoder段使用3D Graph Convolution(3DGC),其具有平移、缩放不变性,生成的Latent feature只包含旋转相关信息。
- 较有特色的是中部橙色框回归出两根正交轴(即作者所称的用两个decoder,正交的原因正文未指出,可能需要看看代码。另:作者认为这和6D表示不同。),然后叉出第三根轴即可得到旋转矩阵。这部分用余弦损失。
下方绿色部分:上面的encoder还输出segment信息,加到最初切出的点云上后过PointNet回归(相对于切出点云重心的)平动和(相对本类平均尺寸的)尺寸。
SGPA
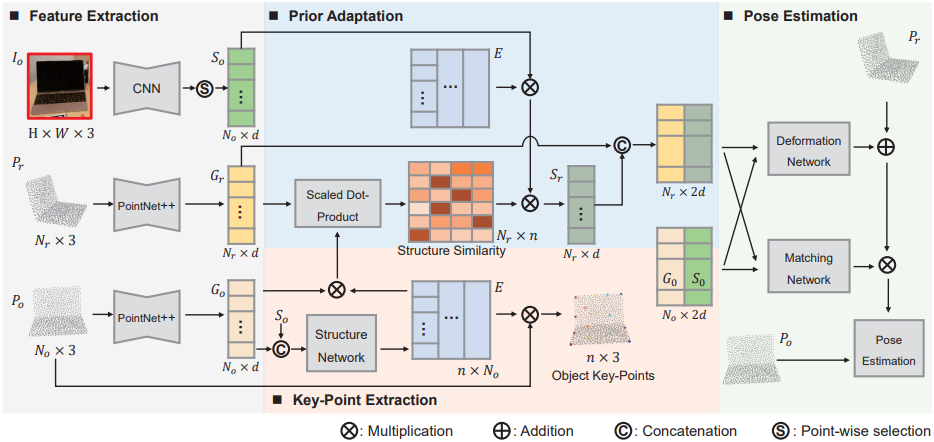
:RGB patch
:先验点云(表示类别信息,文中未限制其获取方式)
:RGBD得到的观测点云
:由逐点取出CNN得出的语义特征组成
,:PointNet++得到的feature
中部获得的过程其实是简化(低秩)的transformer。Structure Network应该就是普通FC(需要查看代码确定),Structure Similarity表现了部分关键点和所有点之间的匹配关系。由于和的点是一一对应的,因此直接把用在的矩阵用在(所提取的特征)上即可。
右部就是上的特征和上的特征结合:首先回归二者间的deformation,其次预测matching关系,最后梅山方法。
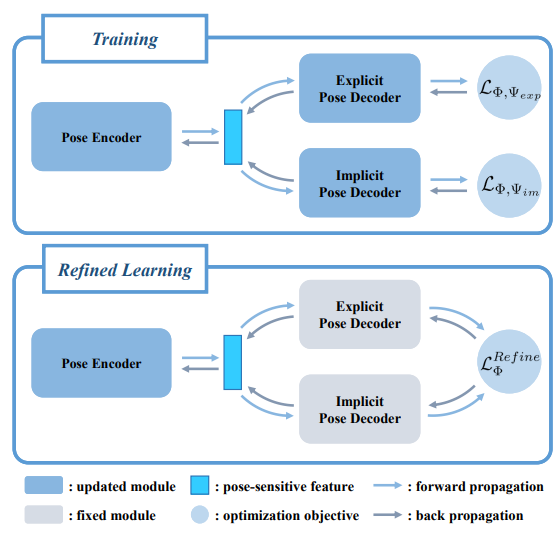
DualPoseNet
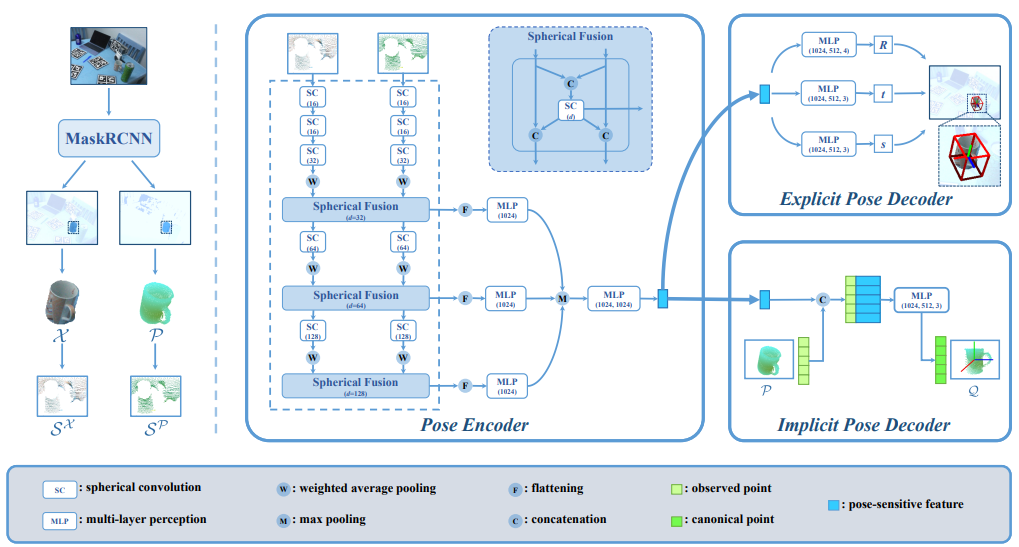
-
左边部分:用maskRCNN做出mask,然后分别提取出可见部分的点云和点云各点对应的RGB值所形成的“RGB点”云。
-
中间部分:以上的都输入Pose Encoder,在不同尺度上交换信息(Fusion),最后得到多尺度位姿特征。
其中,SC指spherical conv,它是在球面上直接做卷积的方法。
注意,这并非直接在空间球面上画出网格之类;实际做法是由于没法显式地画出网格,因此先变换到频域再乘再反变换得解。按:球面上的函数的一个正交基是球谐函数。除spherical conv外,一个较简明的参考为https://blog.goodaudience.com/spherical-convolution-a-theoretical-walk-through-98e98ee64655
在使用SC前需要先把改造为适合使用SC的形式,即先改为图中所示的。
-
右上:Explicit Pose Decoder,由位姿特征回归位姿。
-
右下:Implicit Pose Decoder,由位姿特征和重建canonical中的,即。这里不会直接用来解算位姿,而是通过回归来辅助训练。即训练分两步:
CR-Net
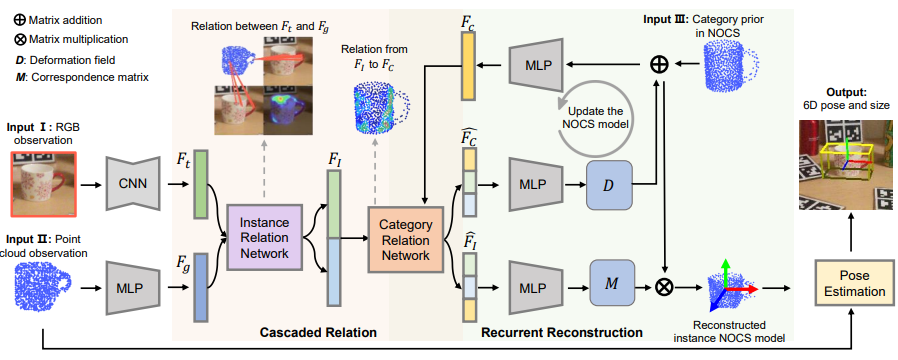
-
首先用maskRCNN之类分割出物体,得到点云和RGB图(patch)
-
随后对RGB图、点云以及Shape Prior(右上角,“Shape Prior”参考SPD)特征提取,分别得到特征(的点数应该相同,是将对应点特征向量提取出来得到的特征;三者的特征维数可以不同)
-
instance relation network(IRN)和category relation network(CRN)有相似的结构。这种网络都必须先确定一个二元关联函数(IRN和CRN可以选择不同的,可以是MLP,transformer等),且其输入和输出都总是成对的。当输入为时,输出为混合后的结果,
图中的是和的连接。
-
D代表deformation,M代表correspondence matrix。多次迭代回归D和M。
-
最后用M确定匹配关系,使用梅山+RANSAC得到6D pose和size。
SAR-Net
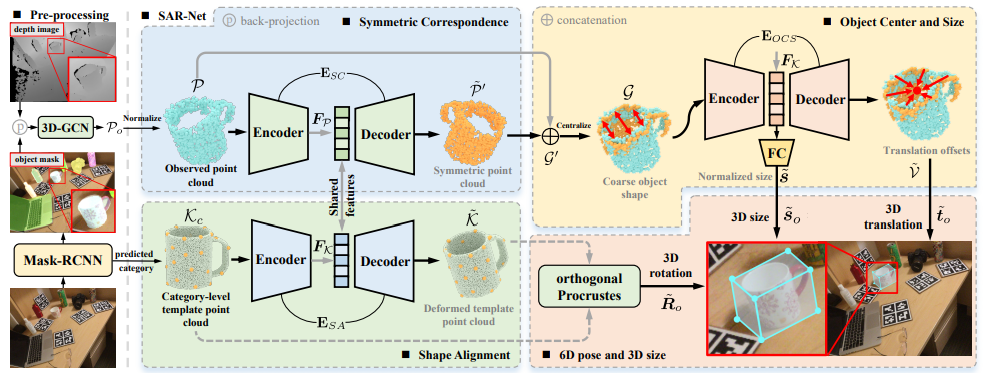
- 开头几步和前面的模型基本一致,不过考虑到分割出的点云可能还带有背景点(segmentation未必是完美的),因此用3D-GCN卷积网络产生质量更好的点云。然后将此点云归一化
- category template直接随机在类中选一个,并用FPS构建一个稀疏的点云。
- Shared features部分可能需要参考源码(尚未开源),其余部分就非常直接了。
GPV-Pose
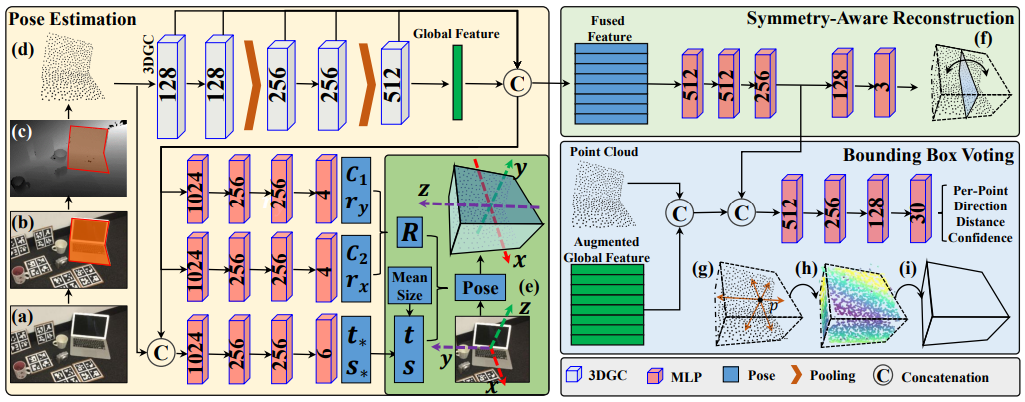
主要组合了三个部分:
- 基于3DGC的encoder
- 对称重建
- bounding box voting
- PP:Point Cloud - Pose
- PBP:Point Cloud - Bounding Box - Pose
- 左边三个MLP:
- 前两个:代表可信度,为回归出的两根轴旋转后的位置(不必正交)。再根据设计的损失即可求出该可信度和轴位置下的一组正交轴即可。二者叉积得z轴位置,即可得到旋转矩阵。
- 第三个:由于3DGC会丢掉位置和尺寸信息,因此要把点云重新拿回来接上。由此回归尺寸和位移。
- 右边的部分:只是为了辅助训练,预测时其实只用左半部分
- 对称重建,不必多言
- bounding box:每个点投向最近的平面。按:Global feature未详细说明,需要check代码。
RBP-Pose
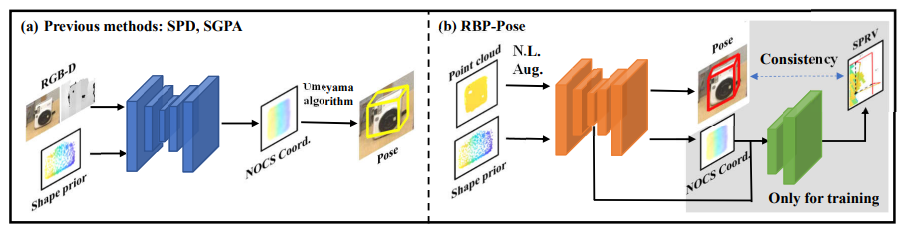
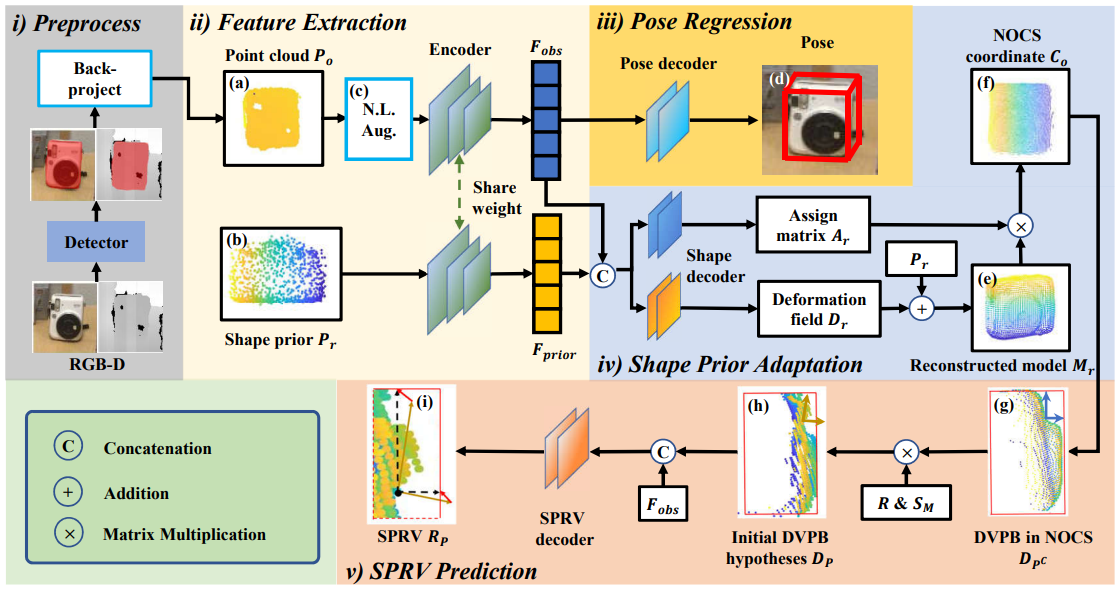
利用了各家之长
- Encoder:3DGC
- Shape Prior:同SPD
- Pose Regression:
- 旋转:同GPV-Pose
- 平移、尺寸:同FS-Net,用所谓residual表示
i~iii三部分就是预测时工作的部分,iv、v用于辅助训练。
- Shape decoder:同SPD
- DVPB:Displacement Vectors from the observed points to the corresponding Projections on the Bounding box,就是输入的点云各点到bounding box最近面的向量(同GPV-Net)
- SPRV:Shape Prior Guided Residual Vectors,其实就是DVPB和真实的DVPB(在世界坐标系中)的差向量。我们要求SPRV Decoder(图中的最下面)回归这一差向量。
- 非线性数据增强(c,N.L.Aug)。增强方式也是根据该类别的形态人工确定的。对于NOCS中的点,使用在对应轴投影长的二次函数确定其各个轴坐标被缩放的比例(这是其中一种方法,另一种方法就是只有一个轴按这种方法缩放,另两个轴按相同比例缩放)
CenterSnap
- 多目标,但是是Single-shot(每类目标只有一个)
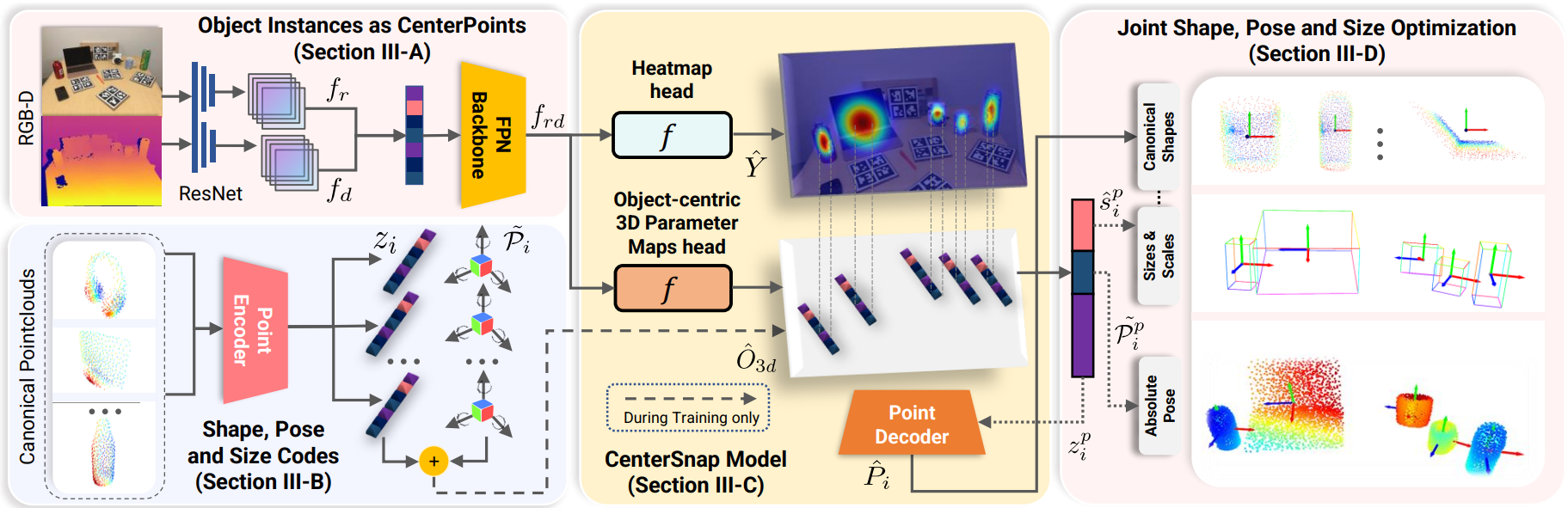
- 首先是检测:RGB图和D图分别过resnet,然后在Channel维合并并通过resnet18FPN获取多尺度特征(拼合在一起),即
- 随后分两个头
- 一头回归Heatmap,指出重心在成像平面的投影位置(训练时Heatmap可以假设为gauss分布,heatmap未必需要和原图有相同分辨率)
- 一头输出向量(包含对点云形状的编码以及位姿、尺寸的编码,全部连接成一个大向量),其training的ground truth(中点云形状编码的部分)通过使用各种类别的模型(要化为NOCS空间的点云)额外训练的Encoder-Decoder中的Encoder生成。(位姿、尺寸的编码就用二者的ground truth生成)
- 回归结果就看这个向量
- 训练过程还要加上对向量中形状编码的decoding(右上角部分),这相当于辅助任务。
- 最后还可以再配个icp
CATRE
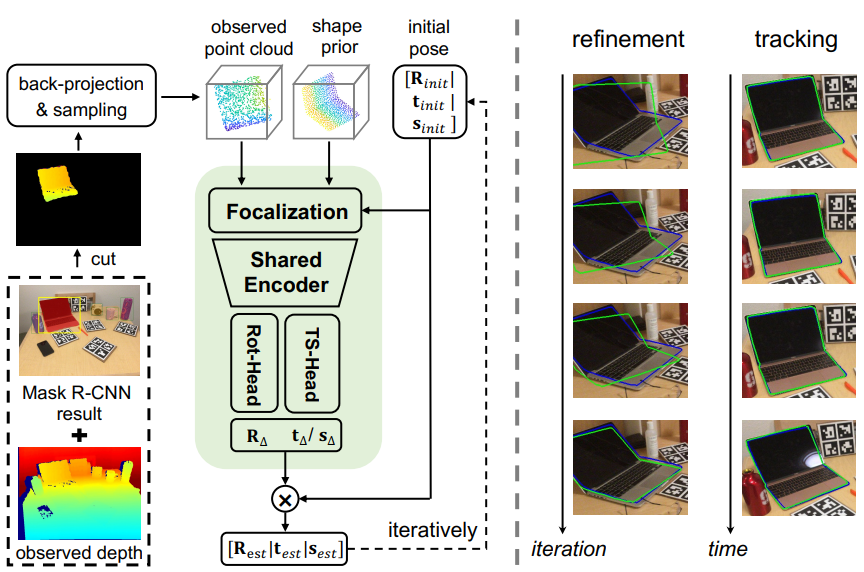
图已经很明显了,只有绿框里的内容需要看看下图:
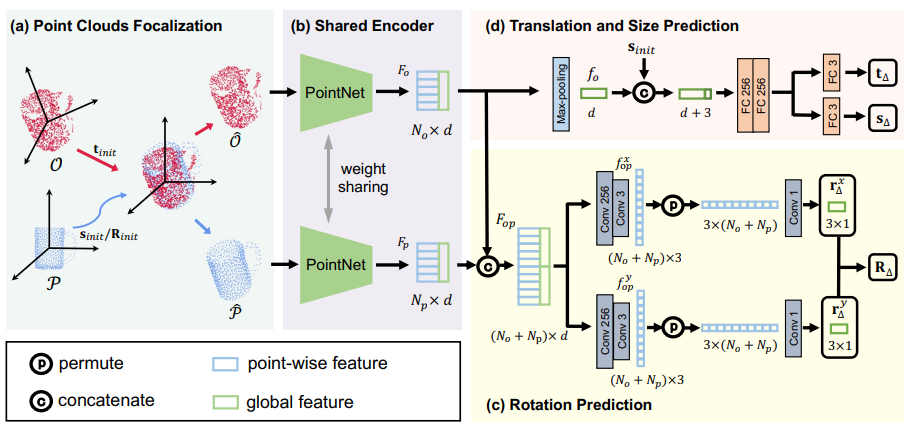
- 文章认为这种结构的shape prior的选取可以更为自由,不限于SPD的办法(但文中实现时还是用的SPD的办法)。
- :observed point cloud
- :shape prior
- 因此,在相同的feature space,故可weight sharing
- 旋转回归类似6D表示法
DPDN
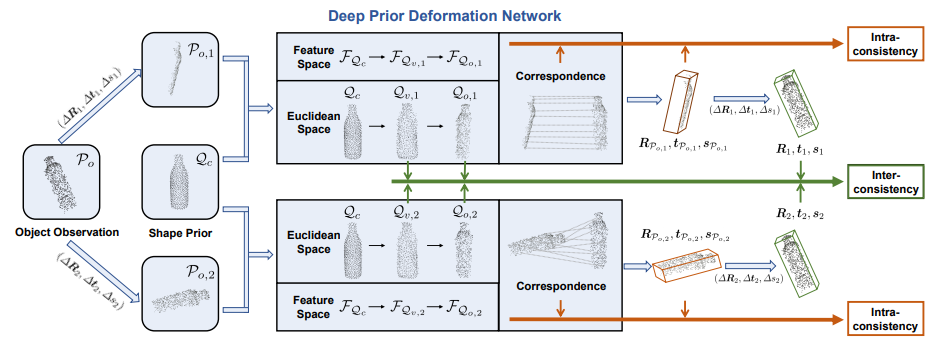
- 提取点云和RGB patch(Object Observation)用maskRCNN+……(同前,上图中未体现此步骤)
- 上图中可知每次训练时都会在位姿上再附加一对位姿,变成一对并行的Object Observation(RGB图不变,因为将RGB的特征加进来时是逐点加入的,因此不会有问题)。(作者认为的self-supervision,还可增强对transformation的敏感性,不过这看起来就是数据增强……)
下图为Deep Prior Deformation Network:
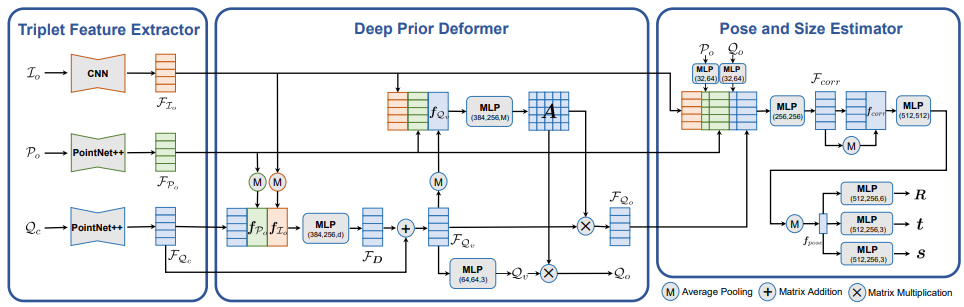
- 第二部分deformer输出的为canonical space且可和一一匹配的特征,就是可以匹配的canonical中的点云。
- 后面的Estimator非常直观
返回前面的inter/intra-consistency
- inter:复合的loss,比较的就是第一张图中两个绿框点云以及对应transformation的相符程度
- intra:衡量和用回归出的transformation作用在上的点云之间的chamfer loss(过去也很常见的loss)
Conclusion
- 大量使用Encoder-Decoder
- 注意Category信息的处理(SPD的shape prior已被大量使用)
- 注意利用2D中的结果和3D中新的backbone
- 控制模型复杂度,简洁未必效果就差(以上就5°5cm而言最佳为CATRE,其结构就挺简洁的)
- 注意如何处理旋转矩阵
- 迭代式优化
附:最糟糕的一篇是RBP-Pose(各种模块都是从之前的文章里挖出来,而且最终效果也并不亮眼;关于最后的“主要”创新点SPRV,不知道作者是否能想起resnet……)然而水水更健康。