介绍位姿追踪问题,并简要列出几种(至少能在Category-level以上解决追踪问题的)解决方法。
论文:
6-PACK(ICRA2020):https://arxiv.org/abs/1910.10750
CAPTRA(ICCV2021):https://arxiv.org/abs/2104.03437
BundleTrack(IROS2021):https://arxiv.org/abs/2108.00516
Definition
在可以对单帧点云(或等效地,RGBD图像等)中的某个物体作Category-level的位姿估计后,我们期望能够对连续的多帧点云(即点云视频,或者4d视频等等)中的某物体在Category-level上做逐帧的位姿估计,即进行位姿追踪。
因此,问题可以形式化为(这里引用6-PACK中的说法):
输入:点云信息、类别标签。
输出:第一帧后各帧相对前一帧位姿的变化量。
最基本的追踪算法就是逐帧使用单帧的位姿估计算法。这样做由于未考虑到相邻帧之间的信息,因此通常效果不佳(但在一些情况下(例如有时会“跟丢”物体)也有其优势)。这则博文只讨论三种利用了帧间信息关联的方法:6-PACK,CAPTRA,BundleTrack。
当然,上述只是一种基本的框架,可根据实情进行变化:
- 为处理铰接物体(articulated object),要求输入部件(part)数、部件初始位姿等。(CAPTRA)
- 为了约束输入,假定只输入刚体。(6-PACK,BundleTrack)
- “位姿”可以改为“位姿和尺度”。(CAPTRA)
- 实用中通常希望能够在线(online)完成预测,即预测某帧时不能利用其后的数据。(CAPTRA,BundleTrack;6-PACK没有明说,但也是在线的)
- 不要求物体的mask(CAPTRA,通过CoodinateNet估计得到mask),或要求输入第一帧的mask(BundleTrack,后续帧的mask由模型自行解决)
6-PACK较为特别:它要求输入物体的尺寸(长宽高),在进行当前帧的位姿估计前会先利用之前的信息对当前帧位姿作一个粗估,这和物体尺寸结合就可以把物体点云从原始数据中割出来。
- 要求要输入第一帧的位姿(6-PACK,CAPTRA,此时输出等价于直接给出各帧的位姿),或不强制要求这一点(BundleTrack)
- 不要求类别标签(BundleTrack,因此BundleTrack是Category-agnostic的,比其他两种Category-level方法更一般化。)
按:个人以为BundleTrack的假设是最协调合理的。CAPTRA要求的部件信息和6-PACK要求的尺寸信息(隐式地要求对物体本身的了解,amodel)在应用中可能不易得到。
6-PACK
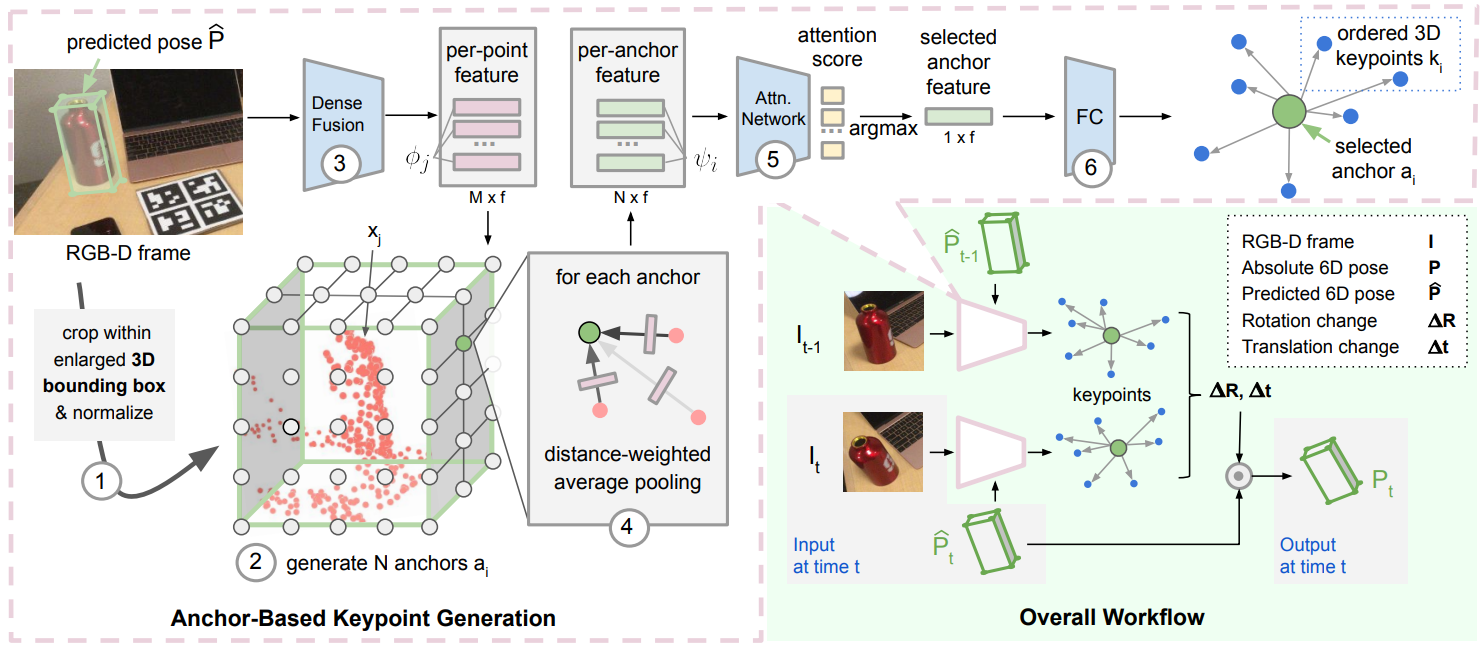
(图源原文)
predicted pose
这个问题文章没在方法部分讲明白,只是在“实验”部分提了一下。作者定义了两种获取所谓“predicted pose”的方法:
- 不包含时间信息的估计(without temporal prediction),即当前帧的predicted pose直接用上一帧的“absolute pose”(即预测的最终被输出的结果,predicted pose并不是最终的预测结果,它只是上文所提到的“粗估”)
- 包含时间信息的估计,即用“上一帧的absolute pose”和“上上帧到上一帧的位姿变化”进行外推。文中提到“匀速模型”,那么想必是用线性插值外推。(有待查看代码验证)
workflow(bottom right)
将当前帧(RGBD)和当前帧的predicted pose输入到关键点模型中(粉色),最后输出(带顺序的,不像点云一样无序的)一组关键点(数量由超参指定),与前一帧的关键点直接按顺序匹配,最后用梅山算法解出位姿(absolute pose)。
anchor-based keypoint generation
首先,6-PACK的物体尺寸(这里指长宽高)是已知量,则根据当前帧的predicted pose可以(近似地)裁剪出和物体相关的点云,随后又按照predicted pose转回canonical frame并单位化(变成近似的NOCS)。
同时,裁出的点云通过Dense Fusion模型获取逐点特征(具体结构略)。
然后,栅格式地取anchor,将各点的特征按由距离确定的权加和汇聚到anchor上。
此后,将逐anchor的特征过attention net(其实就是2层mlp),选出attention最大的anchor的特征。这里在训练时将物体重心的attention设为最大。
最后,将该特征经过FC获得特征点。这里综合应用了多种损失来调整生成的特征点的特点。
CAPTRA
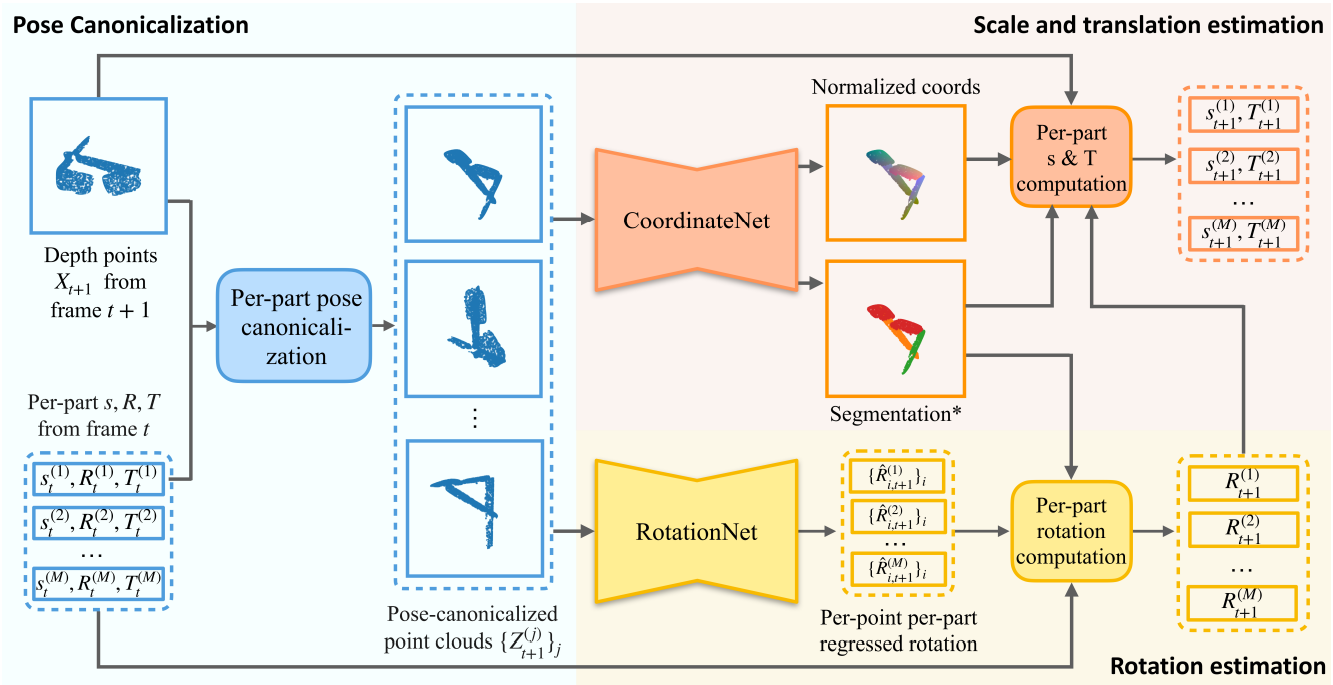
(图源原文)
per-part pose canonicalization
用上一帧的位姿和尺寸把当前帧的整个点云按照各部件的transformation的逆变换转入NPCS(各个部件的NOCS,参考ANCSH)中。当然,这就是一种近似的转换,和真实的NPCS有一定区别。后续部分就将利用这个区别进行位姿估计。
注意:这一步没有分出部件,也没有利用部件的信息。
rotation net
输入各个部件的(近似)NPCS,直接用Pointnet++逐点逐部件地回归出旋转增量估计,随后(利用CoodinateNet的segmetation在同一部件上平均)得到旋转增量,其中代表部件的序号。随后当前帧的旋转矩阵为。
通常而言(例如对单帧的pose estimation而言),直接回归旋转矩阵不是一个好的主意,根本上是因为的拓扑和欧氏空间有一定差异,因此使用点匹配+梅山算法或许有更好的效果。但这里的(根据运动的连续性)通常只在附近一个很小的邻域以内,因此直接回归也是合理的选择。这里作者使用旋转的6D表示(参考往期blog)。
对对称物体有额外的处理方式(略)。
CoordinateNet
还是基于Pointnet++,输入各个部件的(近似)NPCS,一头出mask(如果有RGB图也可用其他方法获取mask),一头出各点对应到真实NPCS的坐标,随后用梅山算法得到尺度和平动向量。
特点在于端到端,没有RANSAC之类的不可微环节。
为什么尺度和位移不和旋转一样直接回归?主要原因还是这是试出来的。
BundleTrack
BundleTrack最大的几个特点:
-
并不只是Category-level的位姿追踪,而是Category-Agnostic级别的通用追踪方法。整个模型的训练不需要使用任何3D点云(包括实例级别和类别级别的)。
当然,这个模型需要训练mask传播网络(transductive-VOS,通过Davis-2017和Youtube-VOS数据集训练)和category-agnostic的特征点提取网络(LF-Net,在ScanNet上训练)。
-
使用多种优化手段(内存池、手撸CUDA)加速模型运行。
为了搞明白CUDA,目前学习OS中……
-
SOTA
-
(自己加的)后半部分使用的是传统方法,又快又可解释。
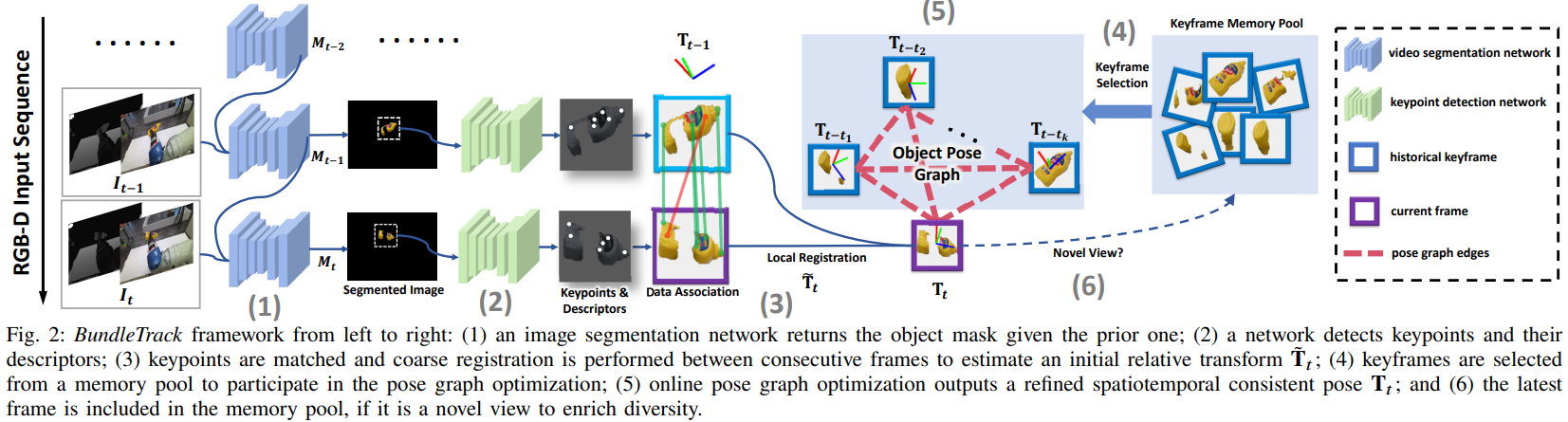
(图源原论文)
Propagating Object Segmentation
这篇文章指出以前的位姿追踪通常使用maskRCNN之类的工具单帧地计算mask,这不仅慢而且没利用时间信息。
事实上,考虑时间信息的mask追踪技术(即逐帧进行传递(Propagating))早已出现。这里直接用现成的transductive-VOS网络。不过这一步只要能把mask搞出来,用任何一种技术都无所谓。
Keypoint Detection,Matching,Local Registration
使用LF-Net即可完成。LF-Net输入两张包含相同场景且视角已知的2D图像(不需要其他的标注,因此方便使用),输出特征点以及匹配关系。
按:LF-Net的训练也非常拉风。虽然包含了不可微环节,但通过使用两个LF-Net拼接得到两个分支,交替优化即可。
参考:Siamese network(孪生网络)(但注意LF-Net并不是孪生网络,只不过参数复制的过程有相似之处)
然后用结合RANSAC的梅山方法得到粗估的位姿变化量。
Keyframe Selection
BundleTrack会始终维护一个内存池,用以存放一堆关键帧(Keyframe)(bundle或许就是指这个内存池)。这些关键帧都是从当前帧以前的帧中选择出来的,且位姿较为多样。
关键帧选择(Keyframe Selection)就是说,在得到粗估的位姿变化量进而得到粗估的位姿后,我们再从关键帧内存池中取出特定数量的关键帧。
选择的标准是:取出的关键帧位姿的集合中加入当前帧的粗估位姿后,位姿两两之间测地距离(geodensic distance)之和最小。
位姿之间的测地距离其实就是指两个位姿之间的刚体运动的旋转表示为角轴式后的转角(即那个因子)。这其实就是要求取出的关键帧组是最接近当前帧的一组关键帧,也正因如此他们才适合用来优化当前帧的位姿。
Online Pose Graph Optimization
随后用选出的关键帧位姿和当前帧位姿组成一张图。这一步的优化目标就是最小化这张图上的一个能量函数。这个能量函数是各边能量函数的总和,而各边的能量函数又可以分成两部分的线性组合(组合系数对各边都相同)
-
指将两帧的关键点按照各自位姿反变换回NOCS后的差距。这个差距用Huber Loss计算。两帧之间关键点的匹配关系如果之前已经算过就用之前已经缓存的数据,否则(这里的两帧未必是连续的前后两帧)通过LF-Net立即计算。
-
是一个比较拉风的重投影损失。它是指把两帧中某一帧(比如取帧)的全部点先用对应的姿态反变换回NOCS,再用另一帧的姿态变换到世界坐标系中,再投影到相机的成像平面,再按照另一帧的RGBD中的D重新lift出3D点云,再用另一帧姿态反变换回NOCS,再用当前帧的姿态变换到世界坐标系得到一个点云。
这个点云就包含了两帧位姿之间的相符程度(协调程度)。用这个点云(点点对应地)减掉帧初始的点云再求范数,就可以得到相符程度的一个度量。再用Huber loss即可算出该重投影损失(能量)。
这样损失函数就搭建好了,需要优化这组关键帧和当前帧的全部位姿。
虽然关键帧都是过去的帧,其位姿预测已经输出过了,但是这些关键帧还可能参加后续帧的图优化环节,因此对关键帧的位姿也要进行优化。
优化方式使用带权的Gauss-Newton方法(权通过能量函数值确定,每轮迭代都会更新)。同时这里的姿态表示也不使用通常的的表示方法,而是使用其李代数表示(当然,还是6D的),优化完了再转换回中去。
Augmenting the Keyframe Memory Pool
经过以上步骤,当前帧的最终姿态便已估计完成,可以输出了。
但此后还需要考虑是否要把当前帧加入到内存池中去。如果当前帧和内存池中已有的帧差距都足够大(差距用旋转的测地距离度量,论文根据实验确定了一个阈值),则为了使内存池中位姿较为多样化(以便对各种位姿都能进行很好的图优化)就可以把当前帧加入内存池。
这里其实就是一种自学习的过程。
是否要考虑内存池会满,所以需要定时删去一些关键帧呢?其实在有“差距足够大”的限制后,关键帧的数量是有上限的。一开始给出足够大的内存就不用管删除的事了。
Conclusion
值得借鉴的地方有:
- NOCS的思想。
- 借用其他领域的好算法。
- 粗估+进一步优化的结构。
- 用多种手段加速模型。
- 注意到单帧位姿和tracking的差异(尤其是估计旋转矩阵的差别)