介绍类别层次(category level)上进行位姿(pose)和尺度估计的经典方法NOCS,重点分析NOCS原理和其数据增强方法CAMERA。
这篇blog也夹带笔者希望记录的其他内容。
论文:https://arxiv.org/abs/1901.02970
Pose Estimation (with ml methods)
一种对(基于ml的)位姿估计方法的分类是将其分为“直接法”和“间接法”。
直接法:即把点云(或图片等其他能反映位姿信息的数据)输入模型,模型直接得到位姿(和尺寸)参数的估计(当然,都是相对canonical frame的运动参数)。最直观的示例如:先用Pointnet之类的结构提取点云特征,随后通过FC获取参数。
在个人的探索过程中发现,这种方法需要注意
-
旋转的表示(可以参考往期blog),尽量选择四元数、6D表示等性质较好的表示方法,以利于优化。
-
损失函数。建议在损失函数中谨慎使用角轴式(Angle-axis)的“角”。因为其计算过程会出现梯度为无穷的情况,即使使用一些方法调整也可能带来过大的梯度(具体参考往期blog)。
简洁且有效的损失函数又有shape aware和shape agnostic之分。最简单的shape agnostic损失——直接看旋转矩阵预测值和真实值之差的范数即可有最基线的效果。(这部分可能之后再写)
-
网络结构可以适度多加点shortcut。
间接法:先用某种方式估计点与点的匹配关系,然后使用梅山方法解决问题。对位姿估计而言,估计点与点的匹配关系就是估计给定点云的各点与canonical frame中的哪个点匹配。可见,canonical frame中的点云完全可以是隐式的,直接由给定的输入点云回归出一个canonical frame空间中的点即可。
由于给定的图片/点云通常都有遮挡,输入点云不全,因此没法找所有点之间的匹配。同时考虑计算效率,因此通常只会找一些特征点之间的匹配关系。这个特征点可以选择bounding box的8个顶点(当然,顶点之间要用序号之类区别开)、用FPS采样得到点等等。NOCS这篇工作中用了一种很妙的方式选择了特征点。
个人观点认为,由于直接法的旋转表示(在使用经典的神经网络构架时)往往存在一些固有的拓扑问题,因此或许间接法是在要使用learning时更加合理的方法。
NOCS
NOCS(Normalized Object Coordinate Space)的作用和canonical space等同。但和通常(用于单物体位姿检测的)canonical space又有所区别:它通过放缩把模型限制在单位正方体中(或者说,模型的tight bounding box边长为1)。
这样做有什么意义呢?
其实NOCS是希望解决一个Category-level的位姿估计问题,因此需要一种新的表示方法。此前的一些位姿估计方法属于Instance-level的范畴(即训练出来的模型就只对一个物体有效),且canonical space中物体的点云属于已知量。此时当然可以不对canonical space做更多的处理(当然如果做一些中心化和缩放,可能对训练过程还是有利的)。
但Category-level的位姿估计所训练出的模型必须对一类物体有效,例如不同型号的相机虽然结构相似,但并不完全相同(见下,图源原paper)。Category-level的模型应该对各个信号相机的位姿估计都有效。

由于我们要求要对一类物体有效,而“一类物体”是没有办法穷举的(训练时,一类物体也只有有限的数个实例有canonical space中的点云数据)。因此必须考虑在没有canonical space中的点云,只知道一些同类物体在canonical space中的点云的情况下定义“位姿”并进行预测。
因此我们要定义“位姿”和“尺寸”,我们可以令一类物体中已知的数个实例的模型都有合理的一致朝向(例如上图中的所有相机的镜头都指向左下方(指纸面上投影)),这样这类中的所有物体就都有一个合理的指向了。另外,由于一类物体的尺寸可以千差万别,为了使同一类物体在canonical space中能尽量“重合”(以有利于不受尺度的影响,有助于训练等),则应该进行某种归一化。这样,用一致朝向+归一化就概括出了对Category level位姿估计的canonical space的要求。这就是NOCS的基本特征。
那么有无已经存在类别信息且已经做好归一化、调整好朝向的点云数据集呢?论文使用的ShapeNetCore恰好满足这样的要求。
NOCS map
下一步就是选择特征点求匹配了。NOCS面对的是RGBD图像(即RGB图像+逐像素的深度信息)。经典的方法会先在RGBD上做目标检测,把对应的物体的区域用mask指出来,然后利用相机外参、内参和深度信息把每个mask区域都折算(lifting)成世界坐标系中的一个点云(当然,由于遮挡等因素,这个点云通常都不完整),随后在这个点云和canonical space中的点云找点与点的配对关系。
在这篇论文中使用了一种新方法。首先,特征点不需要进行额外的选取,直接将mask盖住的点(即物体可见部分)都当做需要找匹配的特征点。其次,直接在二维图像和NOCS之间找匹配,而非先lift后在点云之间找匹配。第三,NOCS中不显式地给出点云,二维像素究竟和NOCS中哪个点匹配是直接用网络回归出来的(这就是NOCS map)。
这样做既简洁,又大大加速计算(在二维图像上卷积比在lifting后的点云做运算更快更便捷),还能利用二维视觉中的预训练权重。唯一潜在的问题是深度信息不参与点匹配的估计可能会导致匹配准确性下降,但取舍后果然还是这篇论文的方法更方便。
因此这篇论文的流程如下:先用maskRCNN在RGB图像上把各个ROI和mask搞出来,然后从ROI处做一个分支,在每个ROI的每个像素上回归出一个NOCS中的点。最后结合mask把各个物体的点云lift出来,用RANSAC改造的梅山方法估计位姿和尺寸即可。(见下,图源原论文,红圈表示maskRCNN的内容(我自己加的))
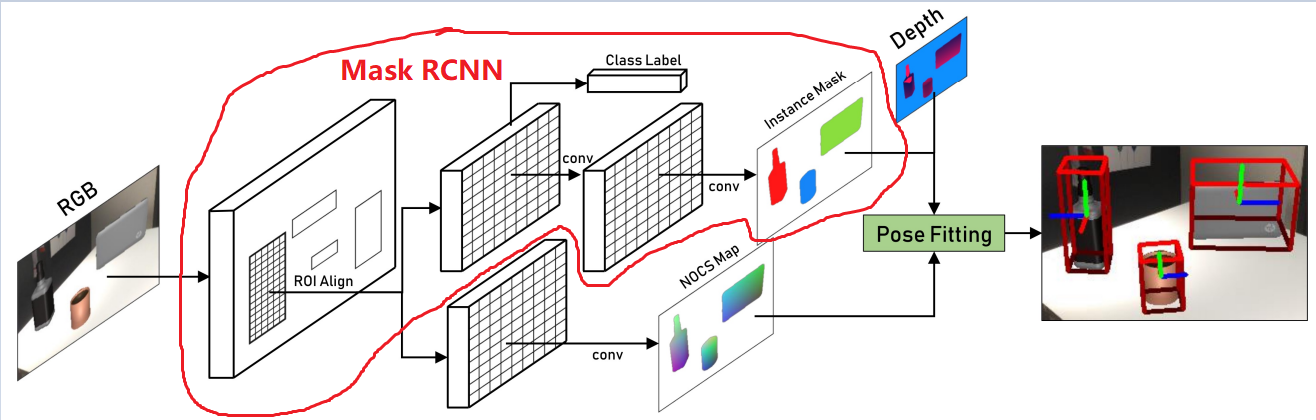
注意:预测NOCS时要为每个类别都预测一个NOCS map(因为预测NOCS map时还不知道当前ROI究竟是哪一个类别),最后再根据类别信息和instance mask分割出正确的NOCS。
不要不分类别地预测NOCS map,否则不同类别之间会发生竞争。(这个道理和maskRCNN最后预测mask的道理一样)。
Data Generation:CAMERA
最后简要提一下论文生成数据的方法:首先准备一系列(带桌面之类大平面的)真实背景图,并把这种大平面的范围检测出来,然后将物体点云进行旋转等操作,并在加上合适的点光源后进行渲染,最后把渲染后的物体“放”在平面上。
这种方法照顾了场景信息(根据论文所述,应该主要指桌面),因此被作者起名为Context-Aware MixEd ReAlity (CAMERA)。
顺带一提,现在一些新数据集(如Hoi4D等)已经有更充足的可用于Category level位姿估计的数据,但这种“考虑上下文”的造数据方法还是值得参考的。