根据个人理解,简要介绍全景分割任务的设定,重点讨论其设立的评价指标。
论文:https://arxiv.org/pdf/1801.00868.pdf
两类物体
可以将计算机视觉中需要辨认的物体分为两类:
-
可数物体(things)
指可以数清”个数“的物体,如人、车之类。
-
不可数物体(stuffs)
指没有”个数“概念的、只能以特定纹理区分的不定形区域,如路面、天空。
两类任务
-
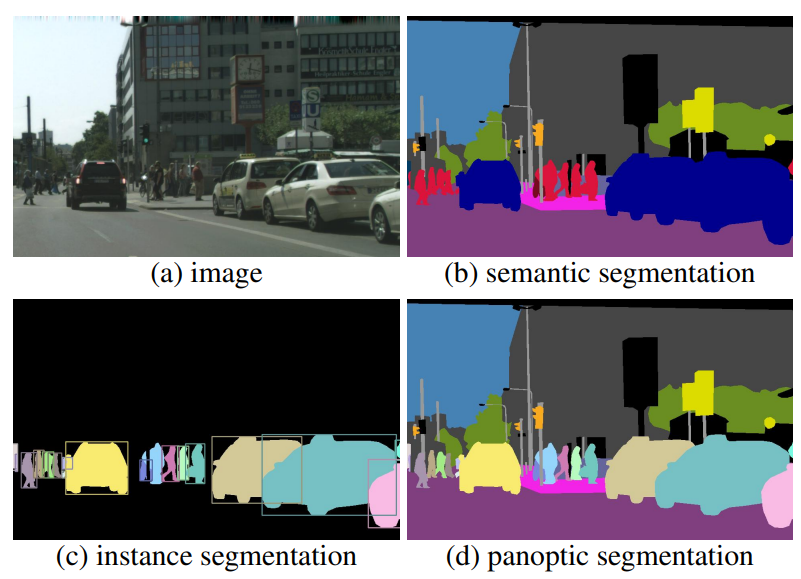
目标检测(object detection)
指找出所有的物体(主要针对可数物体),并用bounding box或mask标示其占据的位置。
对没有检测到物体的图像区域,目标检测任务不予理会。
bounding box或mask有重叠的可能。
-
语义分割(semantic segmentation)
指为图像上的每个像素指定一个类别标签,说明它属于什么样的物体的一部分。
语义分割可以分辨出不可数物体,但是对可数物体而言,语义分割不分辨其个体。例如,当画面中有许多只猫(可数)时,这些猫的像素上的标签都是”猫“,因此没法得知究竟有几只猫。
由于每个像素被指定了唯一的标签,因此不同标签所占据区域是没有交叠的。
两类任务的合并
一个更加理想,也更符合人对环境认知规律的任务是:可以对可数和不可数物体都有较好的识别结果,即既要能识别不可数物体,又要能识别可数物体中的不同个体。
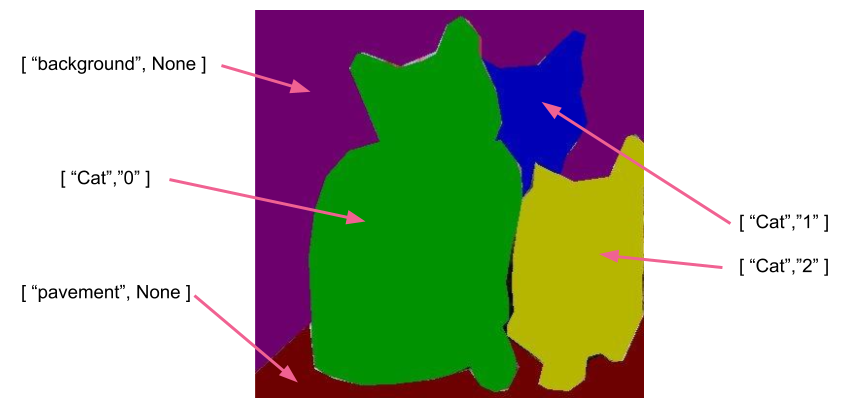
因此,这篇论文提出的新任务(即全景分割(Panoptic Segmentation,PS))是:在语义分割任务的基础上,每个像素除了需要给出一个类别标签,还需要给出一个物体id,以标示这是该类别在该图片中的多个物体中的哪一个。当然,还需要把物体标签分为可数和不可数,不可数的物体id即可直接忽略。
这是几类任务的对比(图源原paper):
评价指标
需要结合分割和识别两个方面的结果来看。
首先当然还是(类似目标检测)将ground truth区域和prediction区域匹配起来。
由于全景识别各个区域也是不重叠的,因此如果ground truth的某个区域和prediction的某个区域IoU>0.5,则prediction中的该区域是prediction中所有区域中唯一一个能与ground truth中该区域IoU>0.5的区域。
因此,当IoU>0.5时,对应的区域可以直接匹配,不必再使用匹配算法确定。当然当不存在IoU>0.5的区域时仍然需要用匹配算法确定匹配,然而论文指出这种情况是极为少见的(因此论文直接把IoU>0.5作为匹配的硬性指标)。因此,这体现了该指标在计算上的便利性。
然后,对ground truth中的每个区域,定义参量如下:
TP = (在prediction中)存在匹配的区域,且标签正确
FN = (在prediction中)不存在匹配的区域
FP = (在prediction中)存在匹配的区域,但标签错误
进而定义:
segmentation quality(SQ)
即匹配成功的区域对们的平均IoU。
recognition quality(RQ)
即分类任务中常讲的F1-score,它是召回率和查准率的调和平均。
panoptic quality(PQ)
,反映了总体的性能。应当在每一类上计算PQ,然后在各类别间取均值得到总体的PQ(以避免类别不均衡的干扰)。